
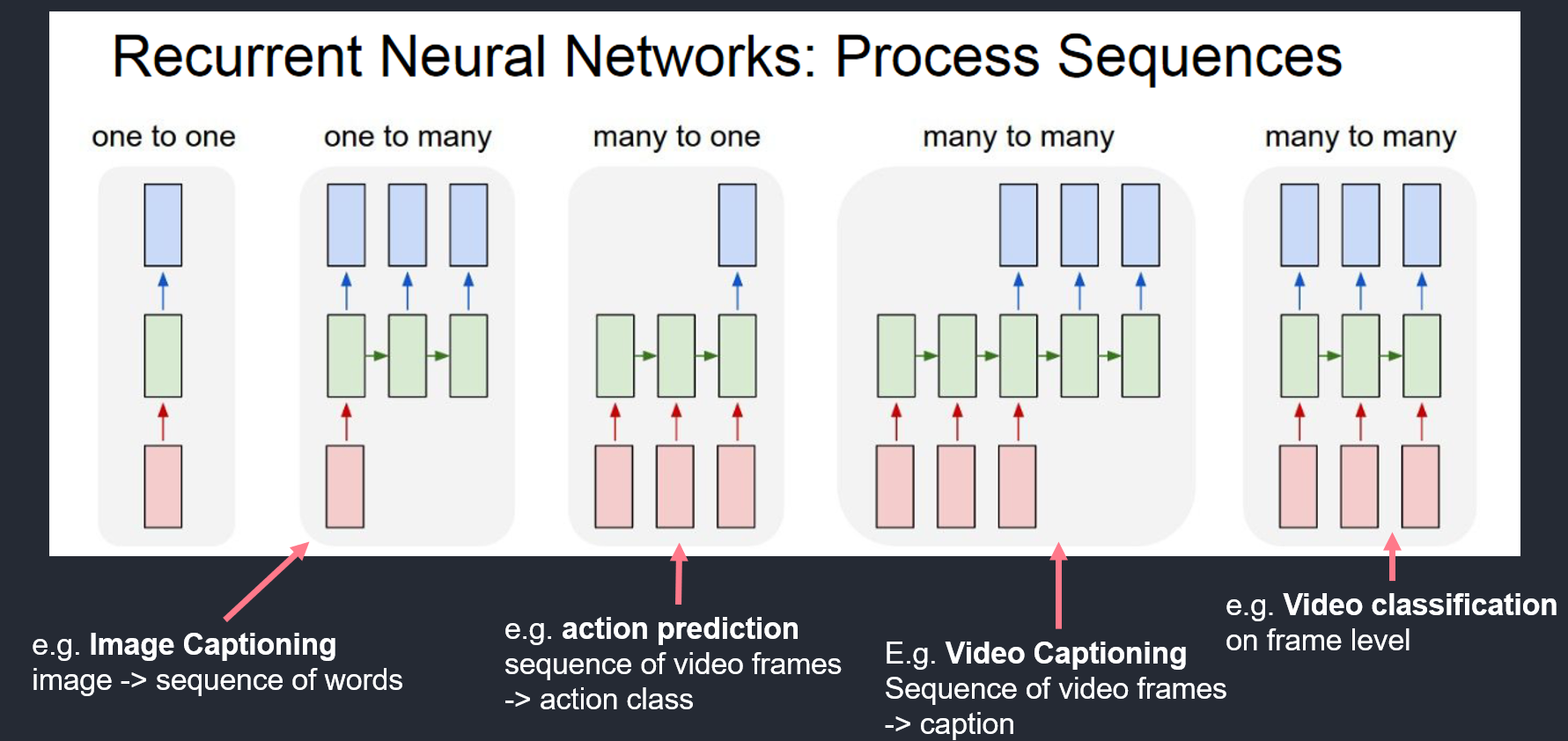
NN basics - RNN
Sequential Data
표현
- 벡터의 벡터
- \(\boldsymbol{x} = (\boldsymbol{x}^{(1)}, \boldsymbol{x}^{(2)},\ldots ,\boldsymbol{x}^{(T)})^{T}\).
- 사전
- BoW
- 빈도수를 세서 \(m\)차원의 벡터로 표현 (\(m\)은 사전 크기)
- 정보 검색에 주로 사용.
- ML에 부적절
- 시간정보가 사라짐
- One hot Encoding
- 한 단어를 표현하는데 m차원 벡터 사용
- 비효율
- 단어간 유사성 측정 불가
- \(\boldsymbol{x}^{(1)} = ((0,0,0,1,0,\ldots)^{T}, (1,0,0,,0,\ldots)^{T}, \ldots)^{T}\).
- word embedding
- w2v
- 단어 사이의 상호작용을 분석하여 새로운 공간으로 변환( 보통 m보다 훨씬 낮은 차원으로 변환)
- BoW
특성
- 순서가 중요함
- 샘플마다 다른 길이
- 문맥 의존성
- 공분산은 의미없고 문맥 의존성이 중요함
- 장기 의존성은 LSTM으로 처리가능함.
RNN
- 시간성
- 순서
- 가변길이
- 문맥 의존성
- 이전 특징을 기억해야함
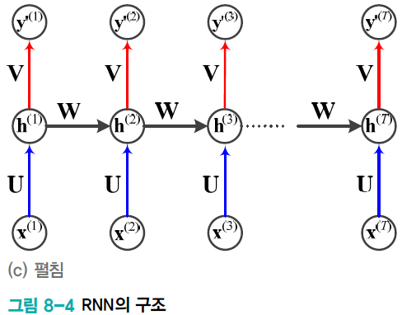
구조
- 입력층, 은닉층, 출력층
- 은닉층이 recurrent edge를 갖음.
- 시간성, 가변길이, 문맥 의존성을 모두 처리
- recurrent edge는 \(t-1\)에 발생한 정보를 \(t\)로 전달하는 역할
수식
\(\boldsymbol{h}^{(t)} = f(\boldsymbol{h}^{(t-1)}, \boldsymbol{x}^{(t)};\theta)\) \(\theta\)는 신경망의 매개변수
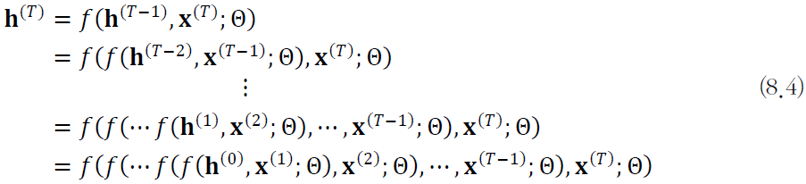
매개변수
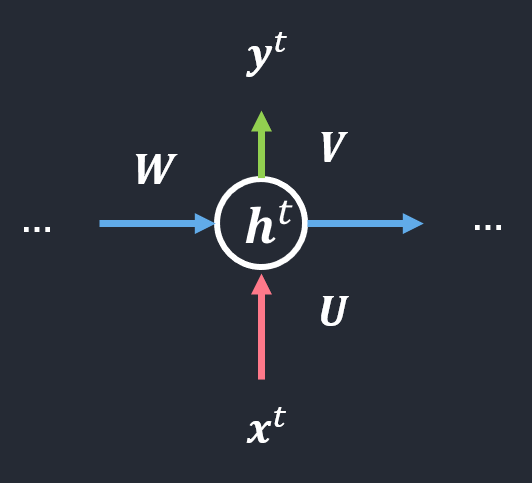
- 순환 신경망의 매개변수(가중치 집합)는 \(\theta = \left\{ \boldsymbol{U}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{b}, \boldsymbol{c} \right\}\)
- \(\boldsymbol{U}\): 입력층과 은닉층을 연결하는 \(p*d\) 행렬
- \(\boldsymbol{W}\): 은닉층과 은닉층을 연결하는 \(p*p\) 행렬
- \(\boldsymbol{V}\): 은닉층과 출력층을 연결하는 \(q*p\) 행렬
- \(\boldsymbol{b}, \boldsymbol{c}\): 바이어스로서 각각 \(p*1\)과 \(q*1\) 행렬
👉 RNN 학습이란 훈련집합을 최적의 성능으로 예측하는 \(\theta\) 값을 찾는 일
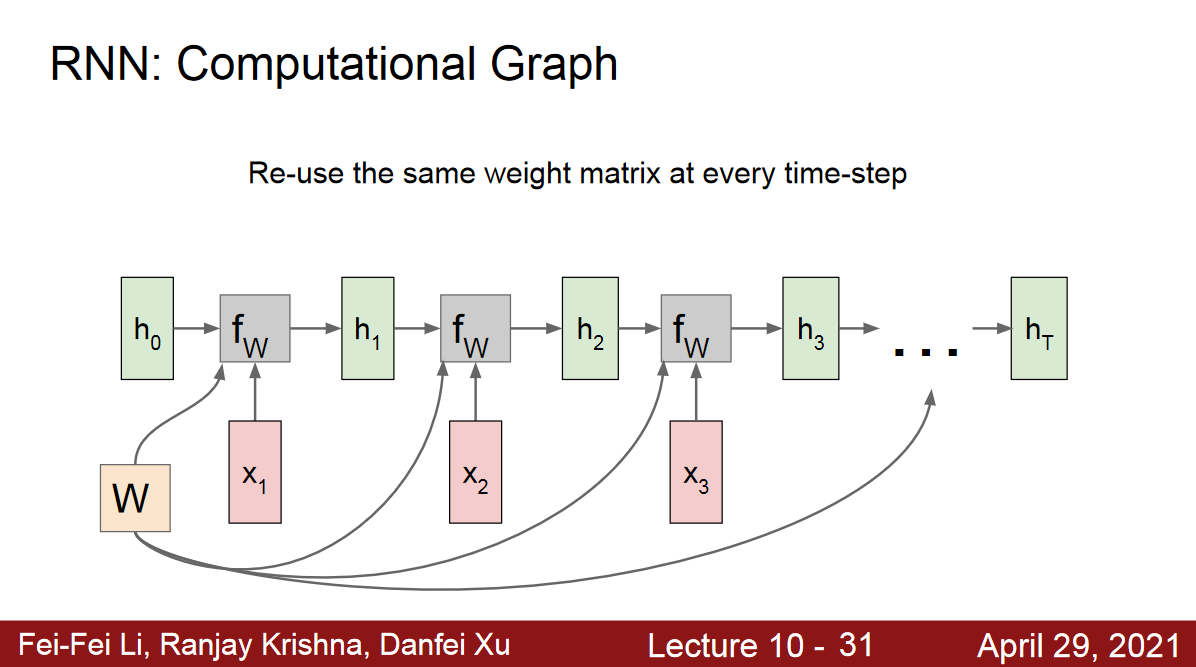
Re-use the same weight matrix at every time-step
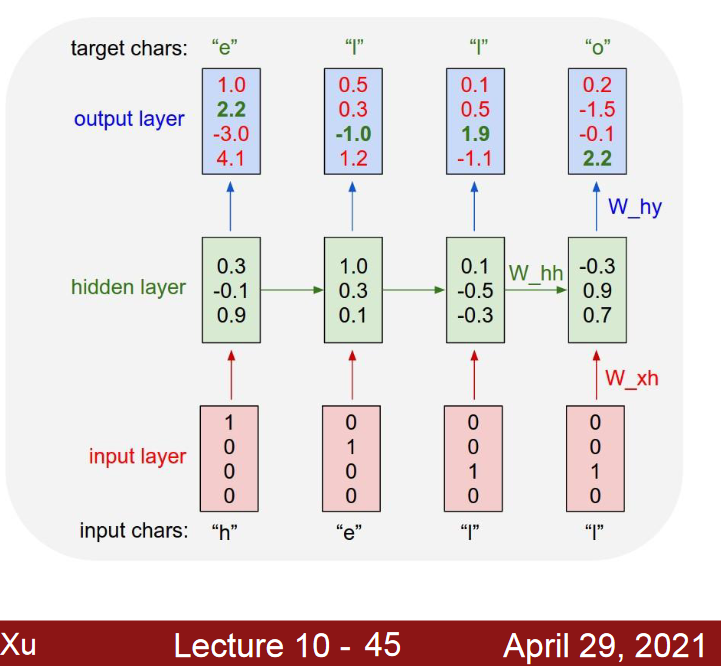
Example: Character-levelLanguage Model
변형
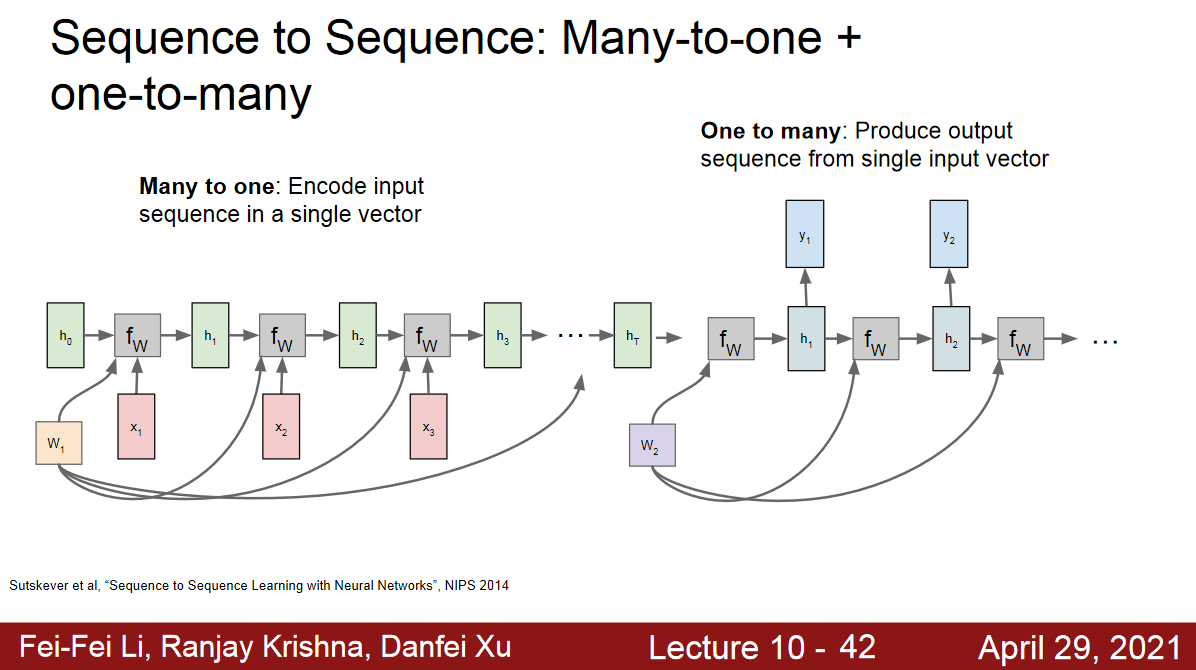
Sequence to Sequence
- Transformer 구조
- Encoder and Decoder
동작
가중치
\(\boldsymbol{U}_{j} = ( u_{j1}, u_{j2}, \ldots, u_{jd} )\) 는 \(\boldsymbol{U}\) 행렬의 \(j\)번째 행(\(h_j\)에 연결된 선의 가중치들)
은닉층
\(h_j^{(t)} = \tau(a_{j}^{t})\), \(j = 1,\ldots,p\)
이 때 \(a_j^{(t)} = \boldsymbol{w}_{j}\boldsymbol{h}^{(t-1)} + \boldsymbol{u}_{j}\boldsymbol{x}^{(t)} + \boldsymbol{b}_{j}\).
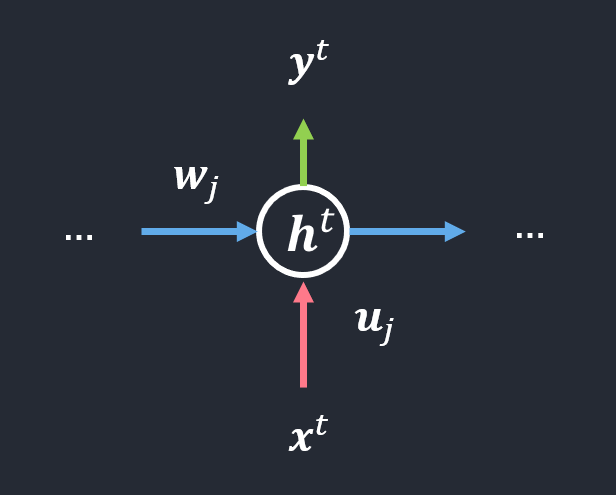
\(\boldsymbol{w}_{j}\boldsymbol{h}^{(t-1)}\)을 제외하면 MLP와 동일.
행렬 표기로 쓰면,
\(h^{(t)} = \tau(a^{t})\), \(\boldsymbol{a}^{(t)} = \boldsymbol{W}\boldsymbol{h}^{(t-1)} + \boldsymbol{U}\boldsymbol{x}^{(t)} + \boldsymbol{b}\)
출력층
\(\boldsymbol{o}^{(t)} = \boldsymbol{V}\boldsymbol{h}^{(t)} + \boldsymbol{c}\).
\(\boldsymbol{y}^{\prime(t)} = softmax(\boldsymbol{o}^{(t)})\).
계산 예제

기억과 문맥 의존성 기능
BPTT 학습 (Backpropagation Through Time)
DMLP와 유사성
- 둘다 입력층, 은닉층, 출력층을 가짐.
DMLP와 차별성
- RNN은 샘플마다 은닉층의 수가 다름
- DMLP는 왼쪽에 입력, 오른쪽에 출력이 있지만, RNN은 매 순간 입력과 출력이 있음
- RNN은 가중치를 공유함
- DMLP는 가중치를 \(𝐖^1,𝐖^𝟐, 𝐖^𝟑,⋯\)로 표기하는데, RNN은 𝐖로 표기
목적함수 정의
- MSE, CrossEntropy, NLL
Gradient 계산
\(\frac{\partial j}{\partial \theta}\) 를 구하려면, \(\theta = \left\{ \boldsymbol{U}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{b}, \boldsymbol{c} \right\}\)이므로 \(\frac{\partial j}{\partial 𝐔},\frac{\partial j}{\partial 𝐖}, \frac{\partial j}{\partial 𝐕}, \frac{\partial j}{\partial 𝐛}, \frac{\partial j}{\partial 𝐜}\) 를 계산해야 함.
\(\boldsymbol{V}\)는 출력에만 영향을 미치므로 \(\frac{\partial j}{\partial 𝐕}\) 계산이 가장 간단함.
\(\frac{\partial j}{\partial 𝐕}\)는 \(q*p\) 행렬
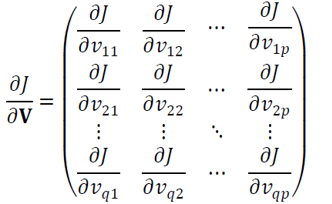
BPTT 알고리즘
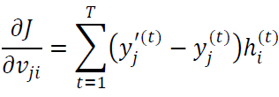
\(𝑣_𝑗𝑖\)로 미분하는 위의 식을 행렬 전체를 위한 식 \(\frac{\partial j}{\partial 𝐕}\)로 확장하고, \(\frac{\partial j}{\partial 𝐔},\frac{\partial j}{\partial 𝐖}, \frac{\partial j}{\partial 𝐕}, \frac{\partial j}{\partial 𝐛}, \frac{\partial j}{\partial 𝐜}\) 까지 유도하면 BPTT가 완성됨
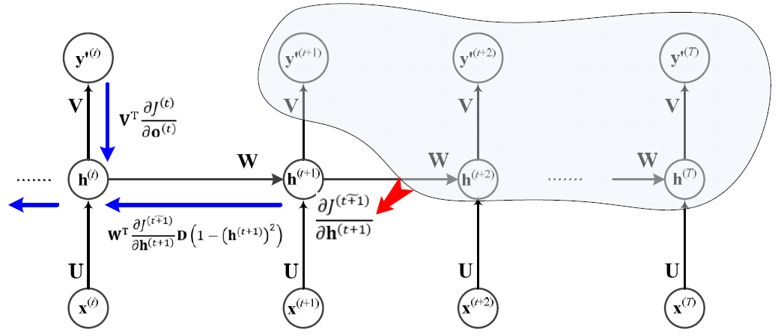
은닉층 미분
순간 \(t\)의 은닉층 값 \(\boldsymbol{h}^{(t)}\)의 미분은 그 이후의 은닉층과 출력층에 영향을 주므로 \(\boldsymbol{v}\)로 미분하는 것보다 복잡.
- 마지막 순간 \(T\)에 대해 미분식을 유도하면,
- \(\frac{\partial J^{(T)}}{\partial \boldsymbol{h}^{(T)}} = \frac{\partial j^{(t)}}{\partial \boldsymbol{o}^{(T)}}\frac{\partial \boldsymbol{o}^{(T)}}{\partial \boldsymbol{h}^{(T)}} = \boldsymbol{V}^{T}\frac{\partial J^{(T)}}{\partial \boldsymbol{o}^{(T)}}\).
- \(\boldsymbol{o}^{(t)} = \boldsymbol{V}\boldsymbol{h}^{t} + \boldsymbol{c}\).
- T-1 순간의 그레이디언트를 유도하면
- \(𝐃(1−(𝐡^((𝑇)) )^2 )\)는 \(𝑖\)번 열의 대각선이 \(1−(ℎ_𝑖^((𝑇)) )^2\)을 가진 대각 행렬
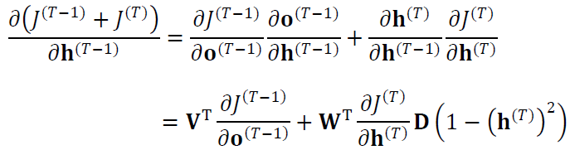
- t 순간으로 일반화하면
- \(𝐽^(\tilde t)\)는 t를 포함하여 이후의 목적함숫값을 모두 더한 값, 즉 \(𝐽^(\tilde t)=𝐽^((𝑡))+𝐽^((𝑡+1))+⋯+𝐽^((𝑇))\).
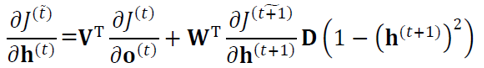
양방향 RNN
양방향 문맥 의존성
왼쪽에서 오른쪽으로만 정보가 흐르는 단방향 RNN의 한계
양방향 RNN (Bidirectional RNN)
t순간의 단어는 앞뒤 단어 정보를 모두 보고 처리.
장기 문맥 의존성
관련된 요소가 멀이 떨어진 상황
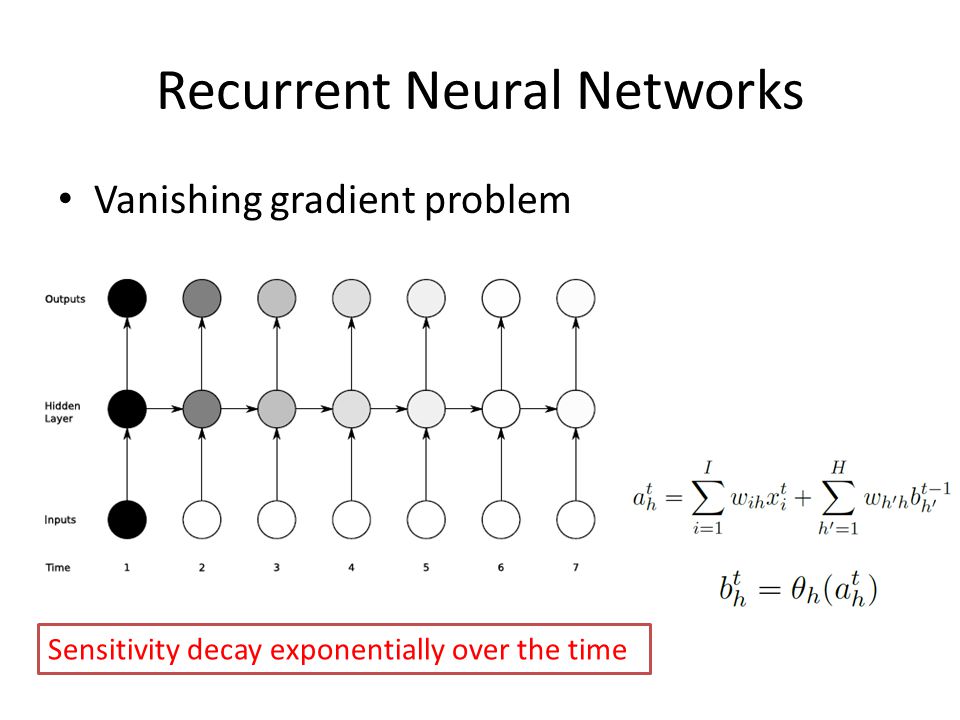
- 문제점
- gradient vanishing
- gradient explosion
- RNN은 CNN보다 심함
- 긴 샘플이 자주 있기 때문.
- 가중치 공유 때문에 같은 값을 계속 곱함.
LSTM 이 해결책
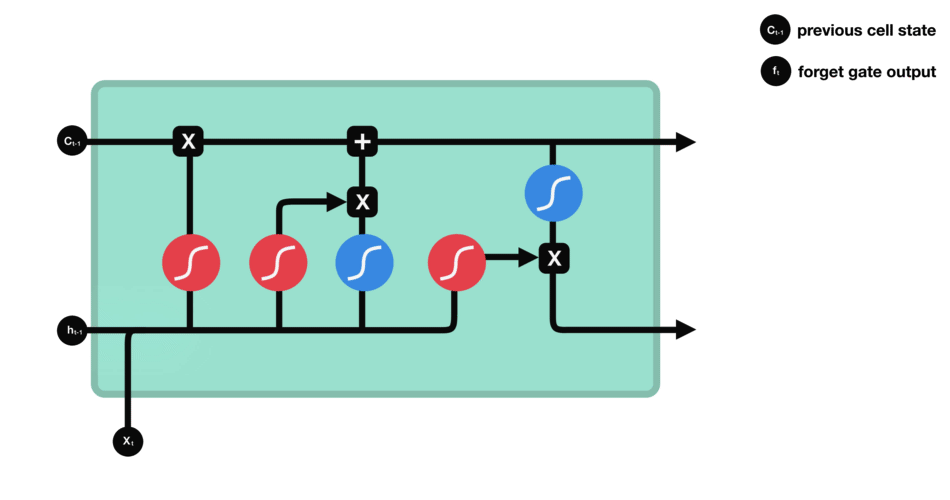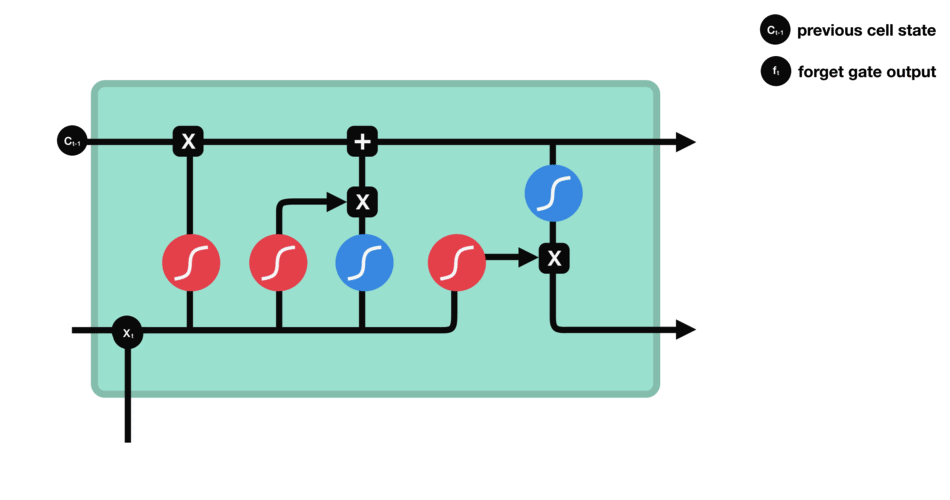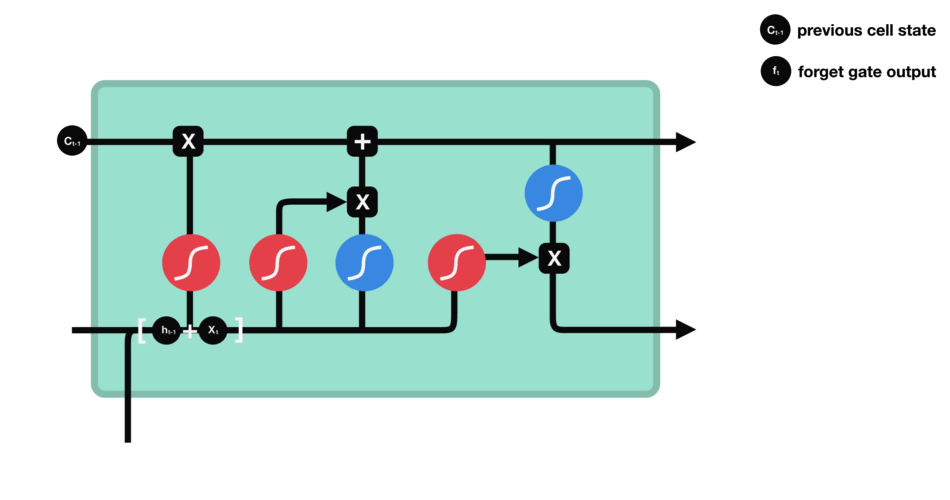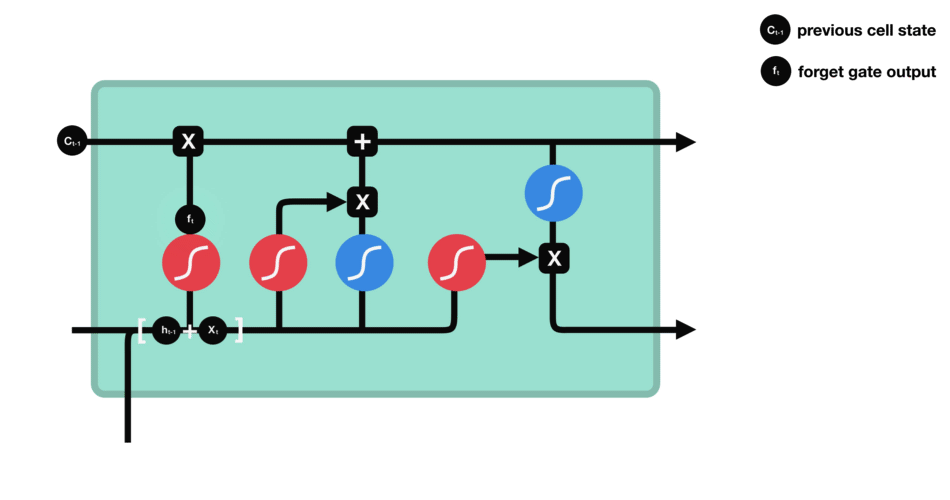
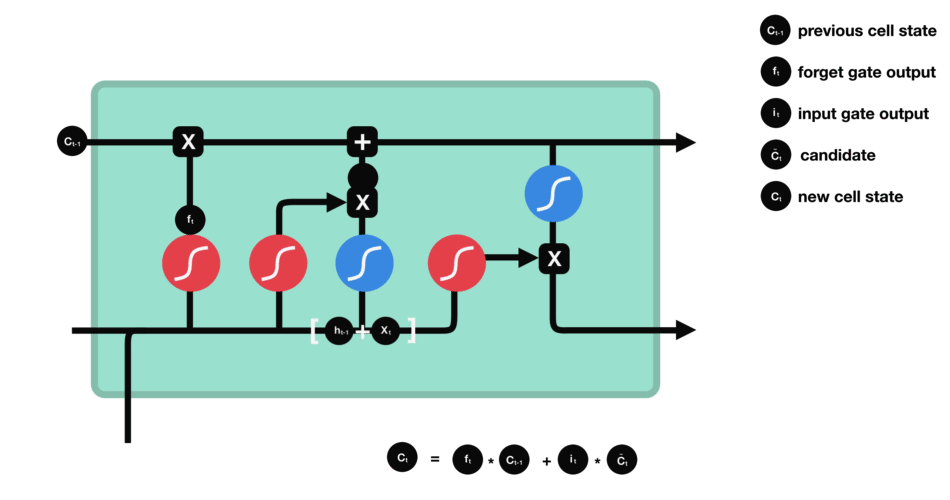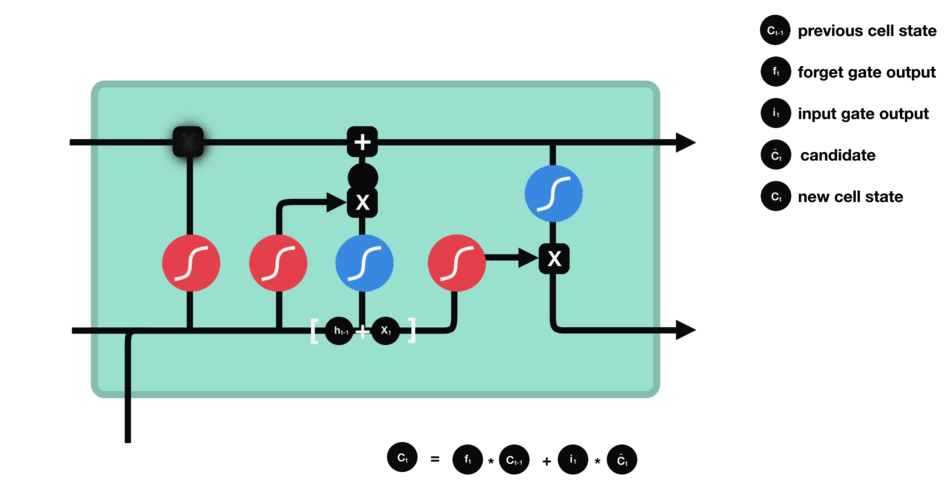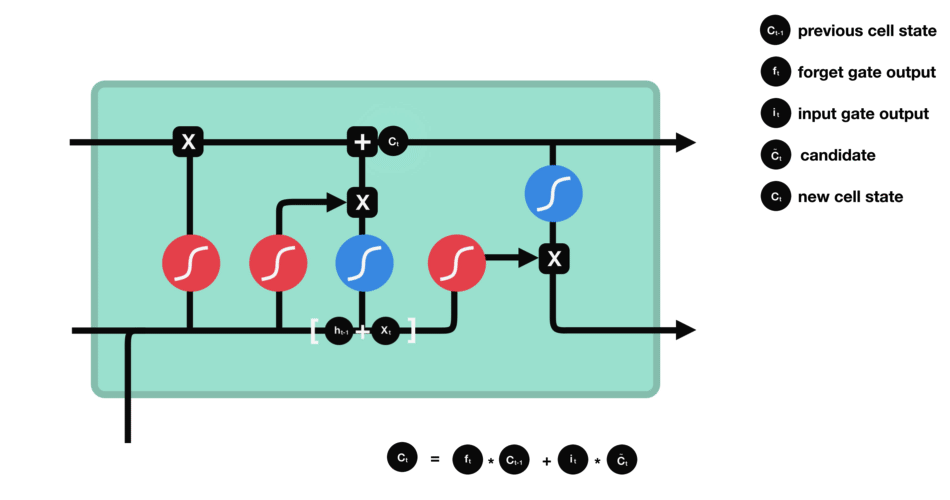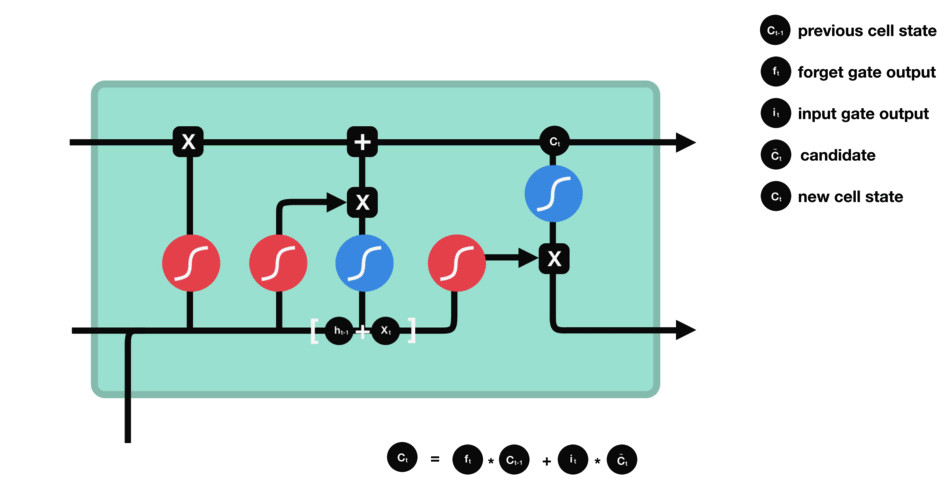
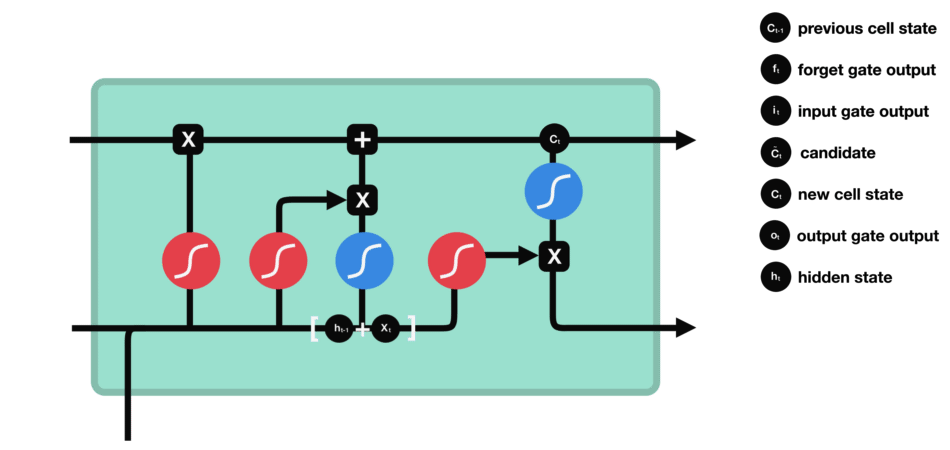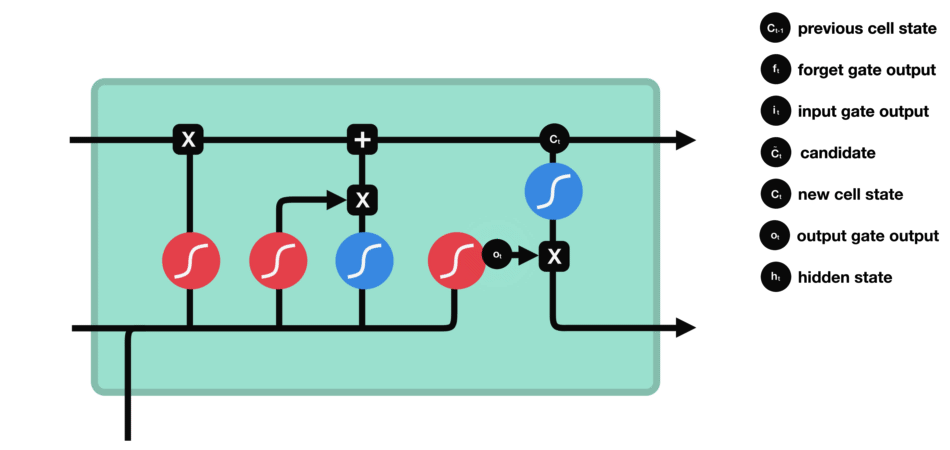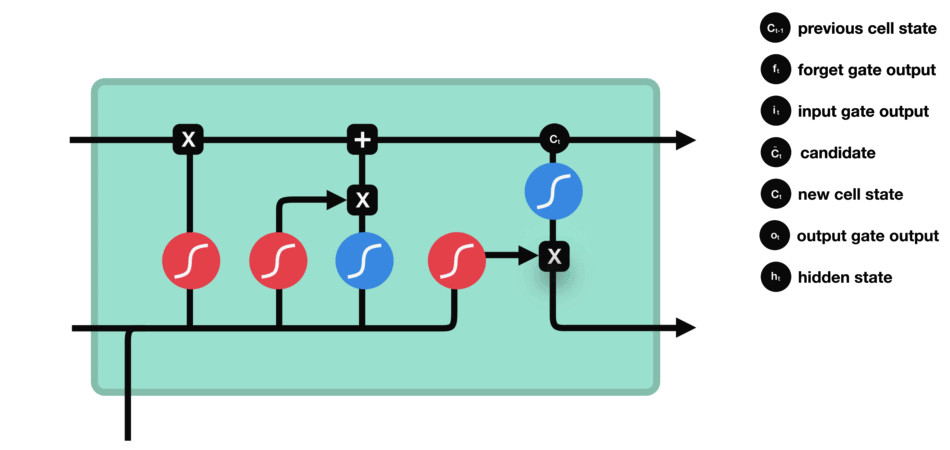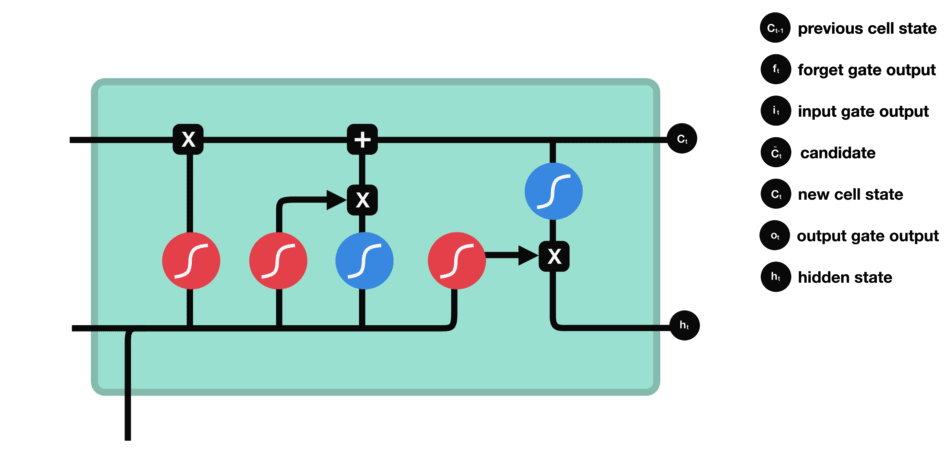
LSTM (Long short term memory)
Gate
- 입력 게이트와 출력 게이트
- 게이트를 열면(⭕) 신호가 흐르고, 닫으면(🚫) 차단됨
- 예, [그림 8-14]에서 t=1에서는 입력만 열렸고, 32와 33에서는 입력과 출력이 모두 열림
- 실제로는 [0,1] 사이의 실숫값으로 개폐 정도를 조절
- 이 값은 학습으로 알아냄
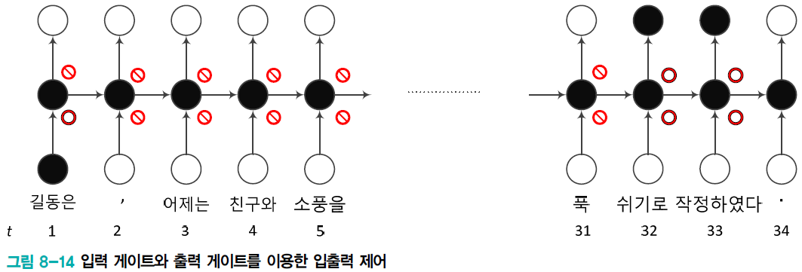
LSTM GATES
- 메모리 블록(셀): 은닉 상태(hidden state) 장기기억
- 망각(forget) gate: 기억 유지 혹은 제거 (1: 유지, 0: 제거)
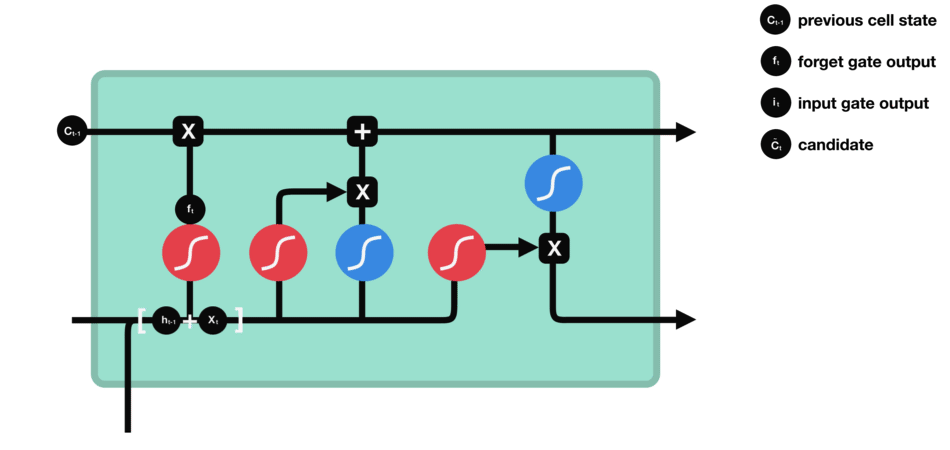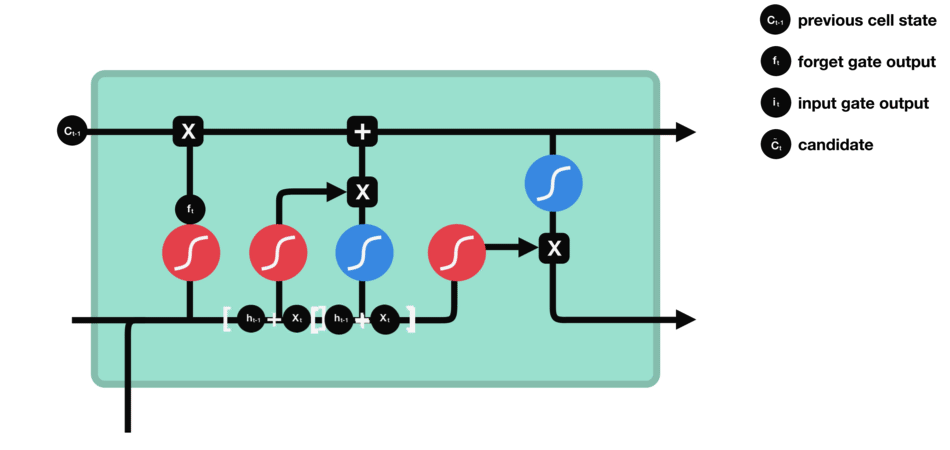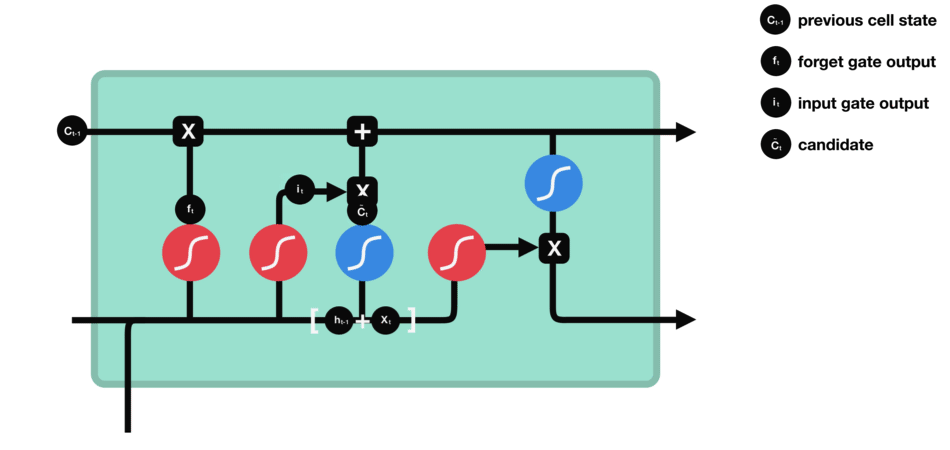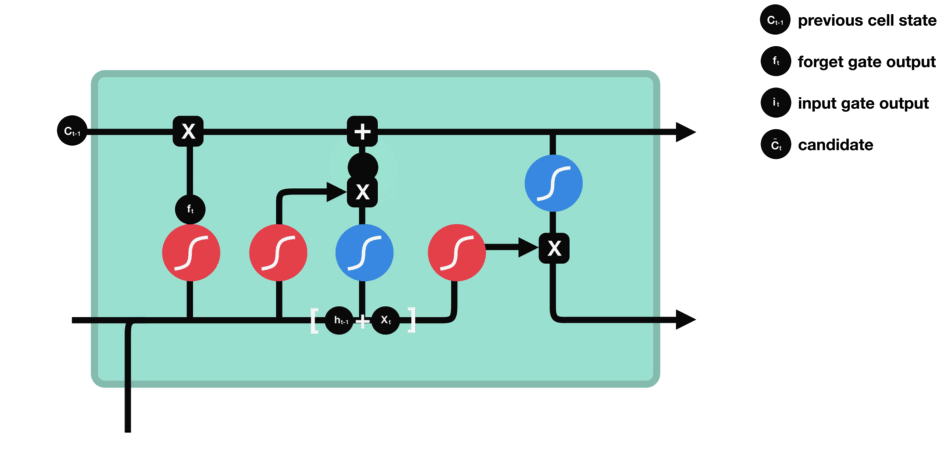
- 입력(input) gate: 입력 연산
- 출력(output) gate: 출력 연산
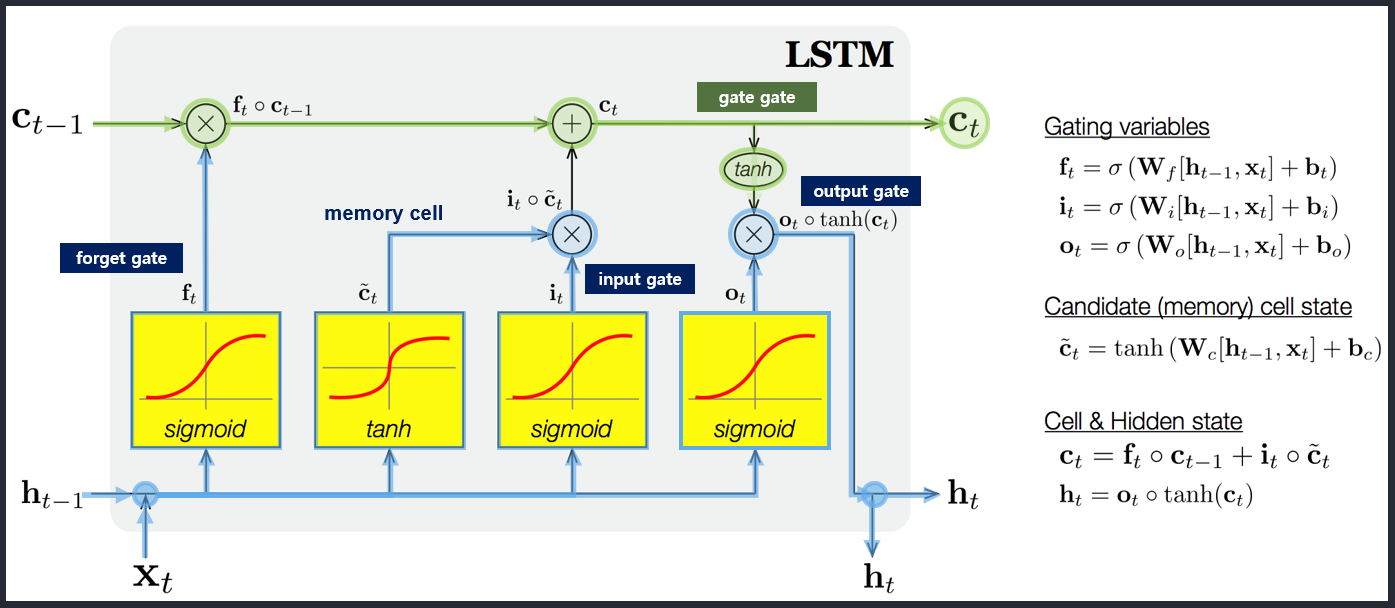
- i: Input gate, whether to write to cell
- f: Forget gate, Whether to erase cell
- o: Output gate, How much to reveal cell
- g: Gate gate(?), How much to write to cell
- \(c_t\): 과거로부터 시각 t까지의 모든 정보 저장. 기억 셀.
- \(h_t\): 기억셀 \(c_t\)를 tanh 함수 적용
- o: output 게이트. 다음 은식 상태 \(h_t\)산출. 입력 \(x_t, h_{t-1}\)을 받음.
- formula: \(o = \sigma(x_t W_{xo} + h_{t-1} W_{ho}+b_o)\)
- return: \(h_t = o \odot tanh(c_t)\)
- f: forget 게이트. 기억셀 \(c_t\) 산출. \(x_t, h_{t-1}\)을 받음.
- formula: \(f = \sigma(x_t W_{xf} + h_{t-1} W_{hf} + b_f)\)
- return: \(c_t = f \odot c_{t-1}\)
- g: tanh 노드. 새로 기억해야 할 정보를 ‘기억셀’에 추가. ⇒ 위 그림에서 \(\tilde{c}_t\)
- formula: \(g = tanh(x_t W_{xg} + h_{t-1} W_{hg} + b_g)\)
- i: input 게이트. 새로 기억해야 할 정보(g의 결과물)의 중요도 판별=가중치.
- formula: \(i = \sigma(x_t W_{xi} + h_{t-1} W_{hi} + b_i)\)
- params 정리
- \(f = \sigma(x_t W_{xf} + h_{t-1} W_{hf} + b_f)\).
- \(g = tanh(x_t W_{xg} + h_{t-1} W_{hg} + b_g)\).
- \(i = \sigma(x_t W_{xi} + h_{t-1} W_{hi} + b_i)\).
- \(o = \sigma(x_t W_{xo} + h_{t-1} W_{ho}+b_o)\).
- \(c_t = f \odot c_{t-1}\).
- \(h_t = o \odot tanh(c_t)\).
RNN과 LSTM의 비교
LSTM은 메모리 셀을 가짐.
LSTM 가중치
- 입력단과 연결하는 \(𝐖^𝑔\), 입력 게이트와 연결하는 \(𝐖^𝒊\), 출력 게이트와 연결하는 \(𝐖^𝒐\)
- 입력층과 은닉층을 연결하는 가중치 \(𝐔\)
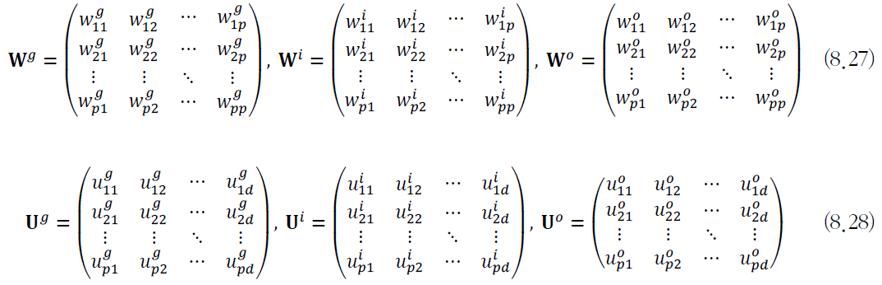
망각 게이트와 핍홀
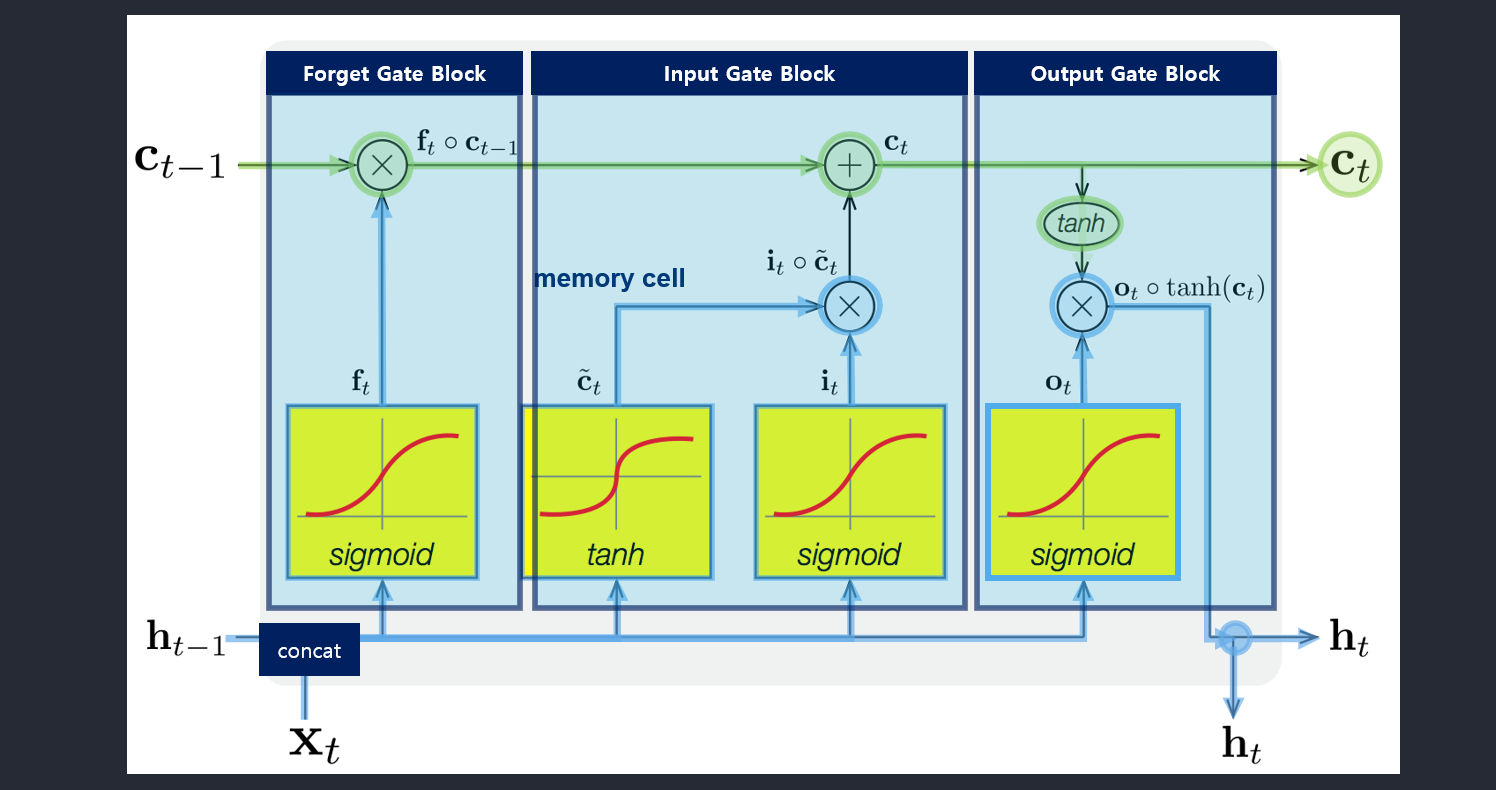
LSTM 동작
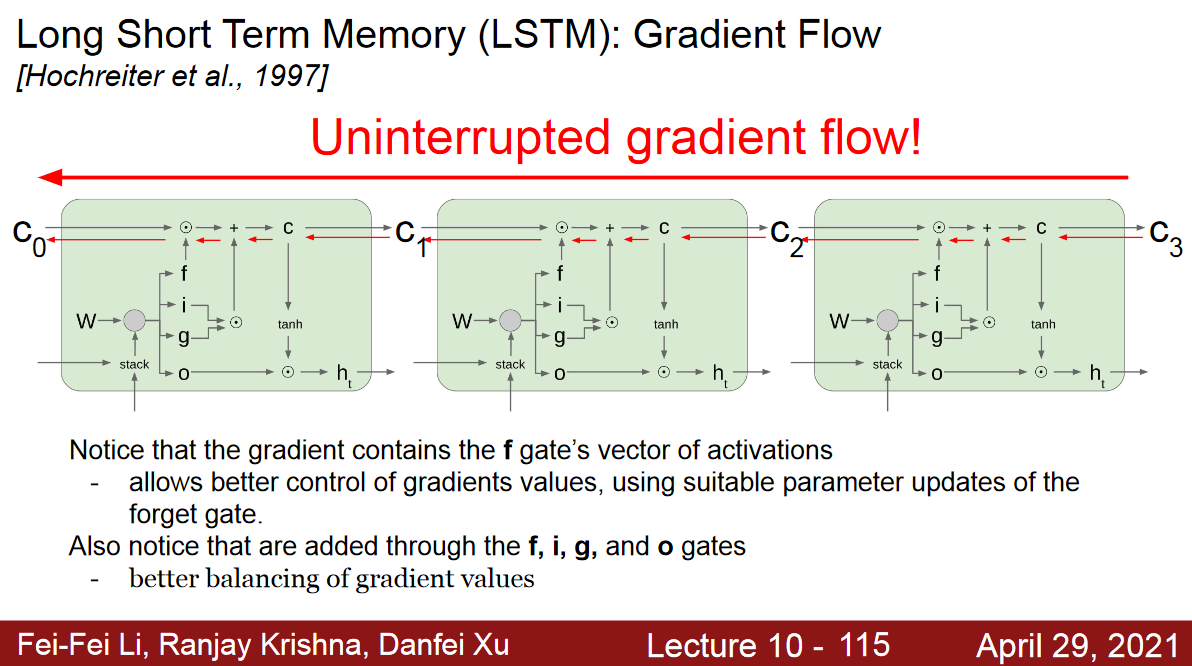
Uninterrupted Gradient Flow!
- forget-gate
- input-gate
- cell-gate
- output-gate
응용 사례
언어 모델
- 문장, 즉 단어 열의 확률분포를 모형화
- 음성 인식기 또는 언어 번역기가 후보로 출력한 문장이 여러 있을 때, 언어 모델로 확률을 계산한 다음 확률이 가장 높은 것을 선택해서 성능을 높임.
- 확률분포를 추정하는 방법
- n-gram
- joint probability
- n을 작게 해야함.
- 확률 추정은 corpus 사용
- 단어가 ohe로 표현되므로 단어간 거리 반영 못함.
- mlp
- rnn
- 확률분포 추정뿐만 아니라 문장 생성 기능까지 갖춤
- 비지도 학습에 해당하여 말뭉치로부터 쉽게 훈련집합 구축가능
- n-gram
- 순환 신경망의 학습
- 말뭉치에 있는 문장을 변환하여 훈련집합 생성후 BPTT 알고리즘 적용
- 일반적으로, 사전학습을 수행한 언어모델을 개별 과제에 맞게 미세 조정함
- 주요 언어모델
- ElMo
- GPT
- BERT
기계 번역
- 언어모델보다 어려움
- 언어 모델은 입력 문장과 출력 문장의 길이가 같은데, 기계 번역은 길이가 서로 다른 seq2seq 문제
- 어순이 다름.
- 현재 DL 기반 기계 번역 방법이 주류
- LSTM을 사용하여 번역 과정 자체를 통째로 학습
- LSTM 2개를 사용(encoder, decoder)
- 가변 길이의 문장을 고정 길이의 특징 벡터로 변환후 가변 길이 문장 생성
- Encoder는 \(\boldsymbol{x}\)를 \(\boldsymbol{h}_Ts\)라는 feature vector로 변환후 Decoder로 \(\boldsymbol{h}_Ts\)를 가지고 문장 생성.

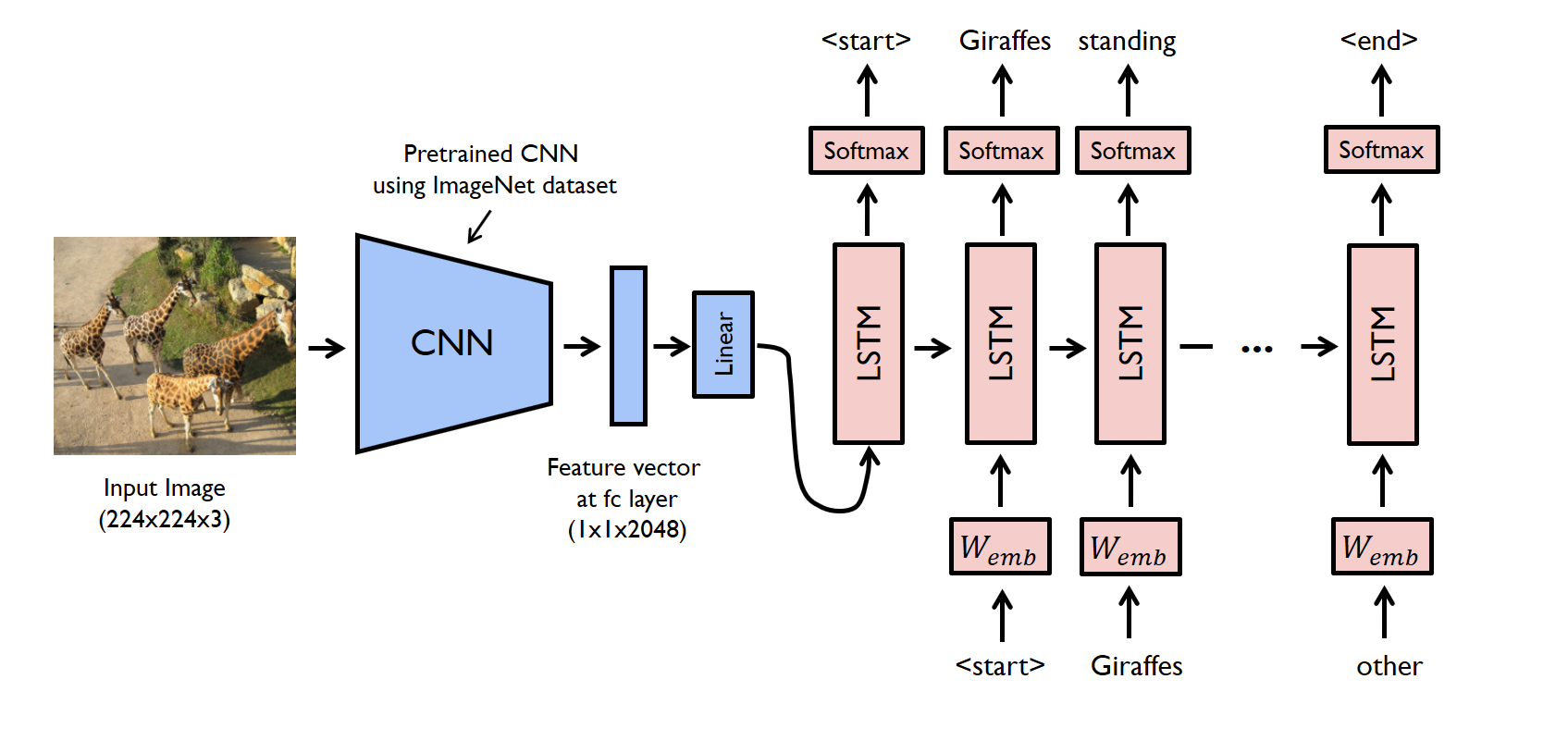
영상 주석 생성
- 영상 속 물체를 검출하고 인식, 물체의 속성과 행위, 물체 간의 상호작용을 알아내는 일
- CNN 으로 영상을 분석하고 인식 + LSTM 문장생성
- CNN: 입력 영상을 단어 임베딩 공간의 특징 벡터로 변환

Appendix
Arrows
⇒, →
⇒ →
Reference
CNN cs231n lecture_10 RNN: http://cs231n.stanford.edu/slides/2021/lecture_8.pdf
LSTM: https://github.com/llSourcell/LSTM_Networks/blob/master/LSTM%20Demo.ipynb
LSTM illustrated guide: https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
Transformer illustrated guide: https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
Attention is All you need: https://youtu.be/4Bdc55j80l8
arrows: https://www.w3schools.com/charsets/ref_utf_arrows.asp
Leave a comment