
NN basics - DL Basics
Computer Vision’s Difficulties
- 관점의 변화로 인해 같은 대상이라도 픽셀값이 다름.
- 배경과 피사체의 구분이 어려움.
- 조명에 따른 변화
- 대상의 기형적 형태
- 가려진 형태
- 같은 클래스안에서의 변화가 큼
CNN
Differ from fully connected NN
Conv
- 각 층의 입출력의 feature map 유지 (filter)
- 영상의 &&를 유지하면서 인접한 정보의 특징을 효과적으로 인식 (영상은 pixel값보다는 spatial information이 중요)
- 각 커널(필터)는 파라미터를 공유함으로써 파라미터수가 적어짐(상대적)(완전연결에서 부분 연결했지만 filter가 이동하면서 파라미터수가 적어짐)
Pool
- 특징을 요약하고 강화.
가변크기 데이터 다루기
conv에서stride, kernel, padding
AlexNet
- ReLU 사용
- 지역 반응 정규화(LRU)
- normalization을 사용 (지금은 안쓰는 방법)
- ReLU 활성화 규제
- 1번째, 3번째 최대 풀링 전 적용
- BN(Batch Normalization)과의 다른점
- LRU: 위치가 비슷한 애들끼리의 정규화
- BN: 학습할때 결정되는 파라미터에 의해서 결정되는 배치간의 차이를 정규화
- overfitting 방지
- Cropping and Mirroring을 사용해서 확대
- Dropout (FC에서 사용)
- 앙상블 적용
- Simple Average
VGG
- 3*3 kernel 사용
- Deeper layers
- conv 8~16, 2~3x deeper over AlexNet
smaller kernel(filter)
- Bigger kernels can be decomposed into several smaller kernels.
- reduce the number of parameters, and deeper network.
5*5filter -> 253*3filter x 2 -> 18(9+9)
- reduce the number of parameters, and deeper network.
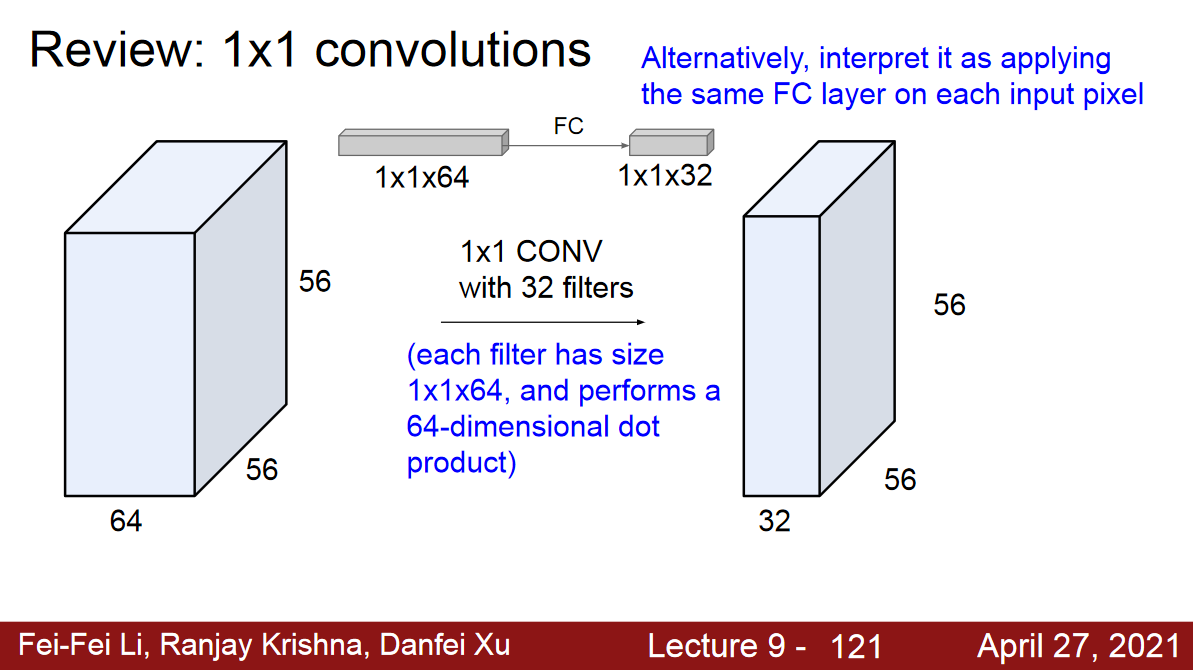
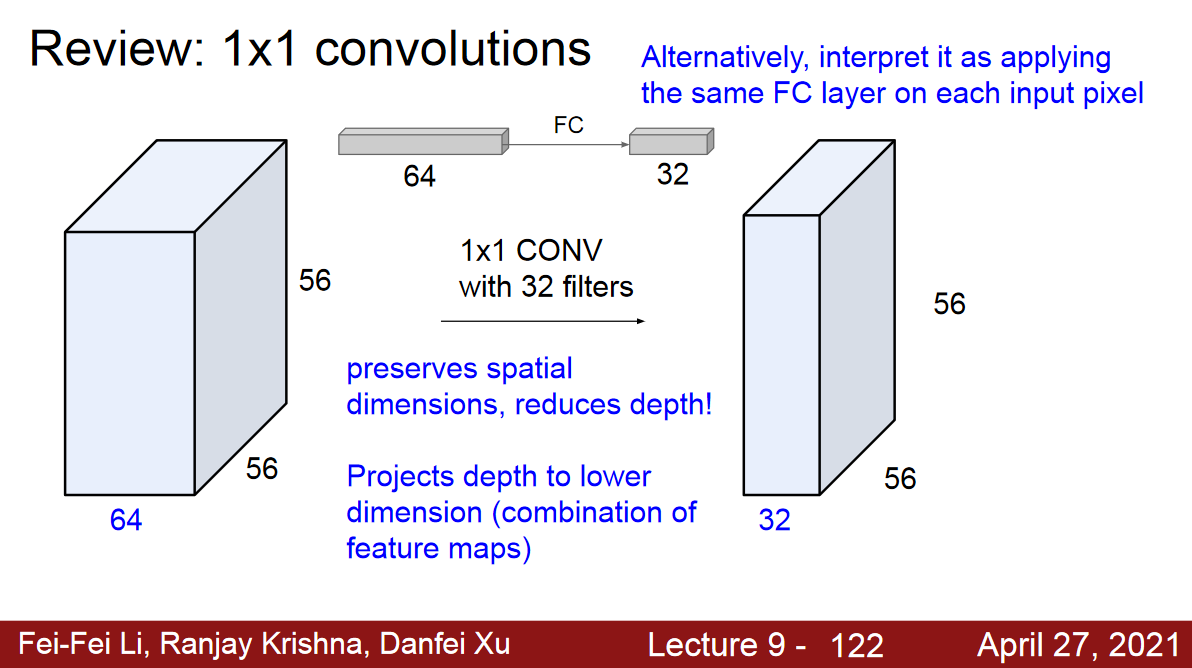
1*1 kernel(filter)
- depth는 L만큼 똑같이 맞춰줌.
- 차원통합
- 차원 축소 효과
- 연산량 감소
m*n의 feature map 8개에1*1커널을 4개 적용 ->m*n의 feature map 4개 출력8*m*n텐서에8*1*1커널을 4개 적용하여4*m*n텐서를 출력
GoogLeNet
인셉션 모듈
- NIN(network in network 논문의 영향을 많이 받음)
- 기존 conv 연산을 MLPConv 연산으로 대체
- 커널대신 비선형 함수를 활성함수로 포함하는 MLP를 사용해서 특징 추출
- micro nn(MLPconv를 사용한 network)가 주어진 특징을 추상화 시도
- 1*1 conv filter
- feature map 개수 줄임
- 연산량 감소
- 비선형성
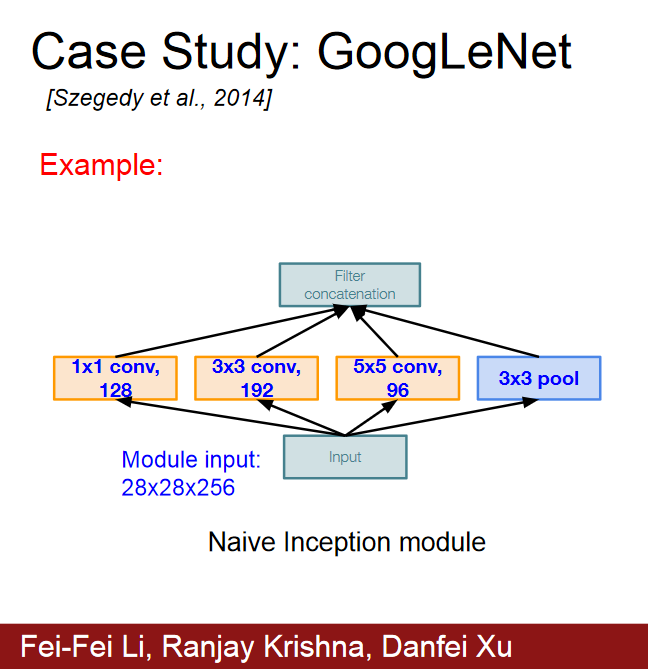
- 기존 conv 연산을 MLPConv 연산으로 대체
- 기존에는 각 layer 간에 하나의 convolution 연산, 하나의 pooling 연산으로 연결을 하였다면, inception module은 총 4가지 서로 다른 연산을 거친 뒤 feature map을 channel 방향으로 합치는 concatenation을 이용하고 있다는 점이 가장 큰 특징
Auxiliary Classifier
- 원 분류기의 backprop 결과와 aux classifier의 결과를 합해서 Gradient Vanishing 완화.
- 학습할때만 사용되고, infer할때는 제거.
GAP 사용
- feature map의 크기가 클 수록 flatten된 vector의 크기도 커지기 때문에 paramter개수가 늘어나는 현상이 있는데, gap를 사용하면 feature map 당 1개의 vector로 average pooling을 하게 되기 때문에 parameter 개수가 0가 되는 효과를 갖게 됨.
- CNN의 대부분의 parameter를 차지하고 있는 Fully-Connected Layer를 NIN 논문에서 제안된 방식인 Global Average Pooling(GAP) 으로 대체하여 parameter 수를 크게 줄이는 효과
- 기존의 FC로 했으면 생겼을 parameter를 0으로 만들어서 파라미터 개수를 줄임.
Resnet
- overfitting이 아니라 optimization이 잘못되었다는 가설에서 시작.
- Very deep networks using residual connections
- Residual Learning 이라는 개념을 이용해서 층 수를 대폭 늘림.
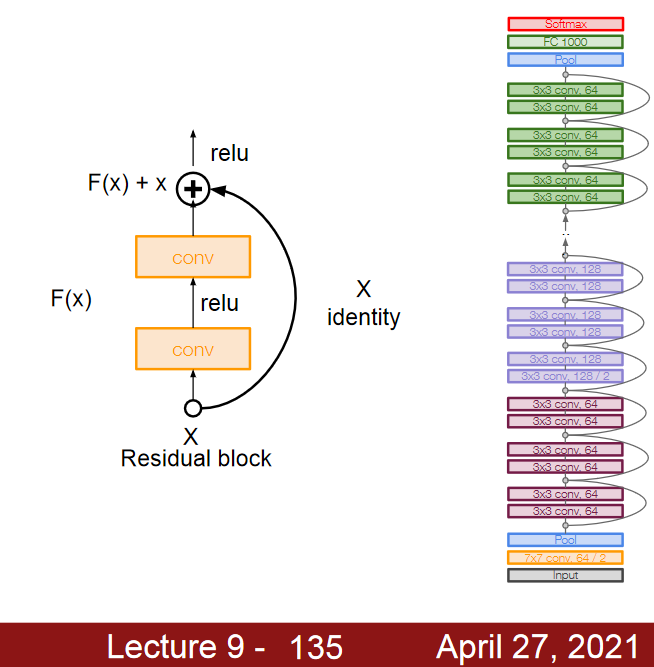
- Gradient Vanishing이 될 가능성이 거의 없음.
생성모델
\(p(x)\)에 대한 모델 (분별 모델은 \(p(y)\))
-
GAN, VAE
-
Appendix
Reference
CNN cs231n: http://cs231n.stanford.edu/slides/2021/lecture_9.pdf
Leave a comment