
06-24 Live Session
CS & Calculus background
Domain Generalization
- The idea of Domain Generalization is to learn from one or multiple training domains, to extract a domain-agnostic model which can be applied to an unseen domain.
Self-Supervised-Learning
- Self-Supervised Learning is proposed for utilizing unlabeled data with the success of supervised learning. Producing a dataset with good labels is expensive, while unlabeled data is being generated all the time. The motivation of Self-Supervised Learning is to make use of the large amount of unlabeled data. The main idea of Self-Supervised Learning is to generate the labels from unlabeled data, according to the structure or characteristics of the data itself, and then train on this unsupervised data in a supervised manner. Self-Supervised Learning is wildly used in representation learning to make a model learn the latent features of the data. This technique is often employed in computer vision, video processing and robot control.
- https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/
- https://paperswithcode.com/task/self-supervised-learning
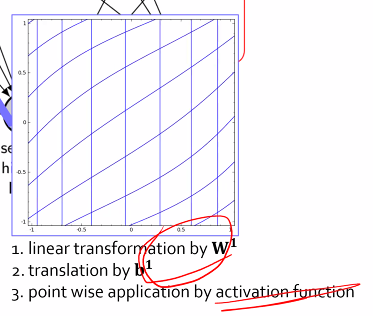
행렬의 곱은 linear transform.
bias가 들어가면 회전.
비선형(activation function)으로 warp
sgd는 lr에 민감하다.
Q & A
또한 모델의 용량이 클때 데이터의 양을 더 많이 수집하면 일반화 능력이 향상된다가 잘 이해가 되지 않습니다. 왜 데이터의 개수가 많으면 12차의 모델이 6차처럼 보이는지 잘 이해가 안됩니다ㅜㅜ
- 매니폴드 가정
- 우리가 생각 하는 데이터의 패턴은 생각보다 심플하다.(유의미한 것은 생각보다 심플하다)
파라미터가 많다.
- 표현능력이 좋아짐.
- 자유도가 높아질수록 표현할 수 있는 능력이 좋아짐.
공간의 접히는 부분을 보면 대칭이 되는 선을 기준으로만 접는거 같은데, 접힐때는 항상 그런식으로만 접히게 되는건가요?
- 이안펠로 책에서 극단적으로 나온것임.
- Relu를 썼을때 그랬음.
- 비슷한것과 다른것을 구분을 크게하기 위함.
계단함수는 활성함수 아닐까요…? 손실함수는 (o-t) L2 or L1 or …로 scalar값으로 알고있습니다.
- 계단함수는 활성함수
- 손실함수는 scalar값.(벡터로 나왔을 경우 1차원, 2차원, 어느 차원으로 기준을?)
피쳐맵이 여러개이면, L층이 병렬로 여러개 있다고 보면 되나요?? 층안 노드들이 피쳐맵의 각각의 요소이고 한 층 자체가 피쳐맵 1개라고 이해하고 있는데 이것이 맞는지 궁금합니다.
- 피쳐맵은 cnn 필터에서 나온 것.
- 레이어 층을 통해 나온 여러 피쳐맵이라고 해도 하나의 데이터로 이해.
선형대수와 확률을 기초부터 공부하고 싶은데, 추천하시는 책이나 강의가 있으신가요? 한국어로 되어있으면 좋겠습니다…
- 기본적인 개념?
- 딥러닝에 rank는 별로 필요하지 않음..
- 그때그때 구글링.
단층퍼셉트론에서의 b 는 임계값의 역할을 한다고 강의에서 들었습니다. 그렇다면 다층 퍼셉트론, deep learning 에서의 각각의 b1, b2 등.. 의 값들도 각 퍼셉트론에서의 임계값 역할을 수행하는 것인가요??
- b값은 임계값은 맞음. 지금은 임계값의 기준을 0으로 맞춰놓고 bias term으로 뺐음.
- 요즘에 나오는 신경망의 activation function의 기준점은 0임. 치우진걸 0으로 옮겨놓기 위해 bias term을 하나 더 줌.
ReLU 함수를 이용해서 비선형 곡선 함수를 근사할 수 있는 근거가 뭔지 알고싶습니다
- 이론적인 부분
차수는 다항식의 모델을 쓰는 경우에 차수가 많아지면 모델의 파라미터가 많아지는 것.
nips, cvpr 논문을 진행해보는 것도..?
Leave a comment