
SQL Analysis - JOIN & 리뷰
JOIN
SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 MERGE 하는데 사용됨. 이는 스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는 데 사용.
JOIN의 결과는 방식에 상관없이 양쪽의 필드를 모두 가진 새로운 테이블을 만들어내게 됨.
조인의 방식에 따라 다음 두 가지가 달라짐.
- 어떤 레코드들이 선택
- 어떤 필드들이 채워지는 지
JOIN 문법
SELECT A.*, B.*
FROM raw_data.table1 A
XXXX JOIN raw_data.table2 B ON A.key1 = B.key1 and A.key2 = B.key2
WHERE A.ts >= '2019-01-01';
- XXXX: INNER, FULL, LEFT, RIGHT, CROSS
JOIN 시 고려해야할 점
- 먼저 중복 레코드가 없고 PK uniqueness가 보장됨을 체크
- 아주 중요
- JOIN하는 테이블간의 관계를 명확하게 정의
- One to one
- 완전한 one to one: user_session_channel & session_timestamp
- 한쪽이 부분집합이 되는 one to one: user_session_channel & session_transaction
- One to many (order vs. order_items)
- 이 경우 중복이 더 큰 문제 ⇒ 증폭
- Many to one
- 방향만 바꾸면 one to many로 보는 것과 사실상 동일
- Many to Many
- 이런 경우는 드뭄.
- one to one 또는 one to many로 바꾸는 것이 가능하다면 변환
- One to one
- 어느 테이블을 베이스로 잡을지(
FROM에 사용할지) 결정해야 함
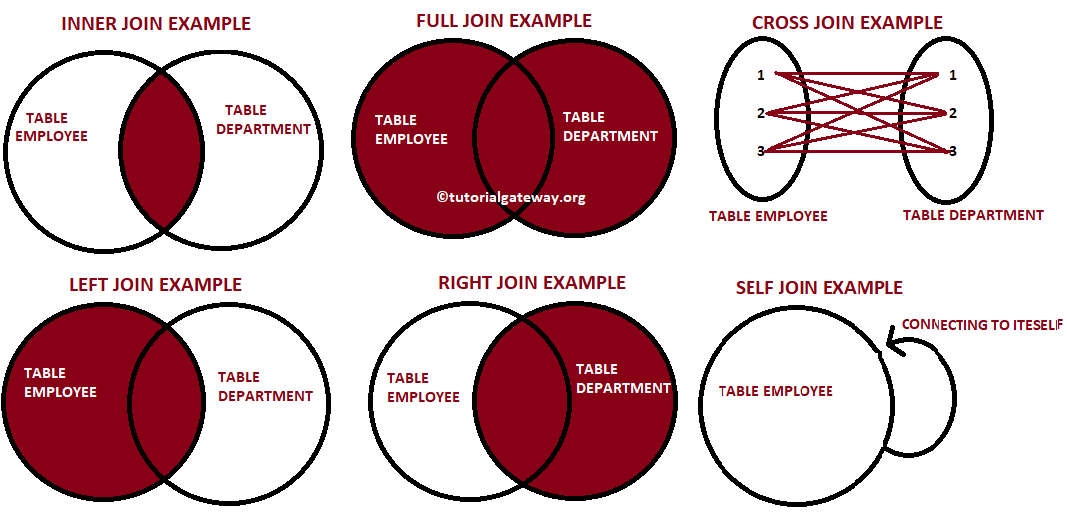
다양한 종류의 JOIN
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL OUTER JOIN
- SELF JOIN
-
CROSS JOIN
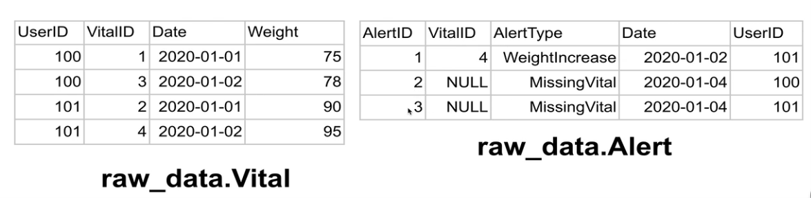
- 예제 테이블
-
ex
- raw_data.Vital
-
userid vitalid date weight 100 1 2020-01-01 75 100 3 2020-01-02 78 101 2 2020-01-01 90 101 4 2020-01-02 95
-
- raw_data.Alert
-
alertid vitalid alerttype data userid 1 4 WeightIncrease 2020-01-02 101 2 NULL MissingVital 2020-01-04 100 3 NULL MissingVital 2020-01-04 101
-
INNER JOIN
- 양쪽 테이블에서 매치가 되는 레코드들만 리턴
- 양쪽 테이블의 필드가 모두 채워진 상태로 리턴
SELECT * FROM raw_data.Vital v JOIN raw_data.Alert a ON v.vitalID = a.vitalID; -
userid vitalid date weight alertid vitalid_1 alerttype date_1 userid_1 101 4 2020-01-02 95 1 4 WeightIncrease 2020-01-01 101 
- 매칭되는 레코드는 하나 뿐이기 때문.
LEFT JOIN
- 왼쪽 테이블(base)의 모든 레코드들을 리턴함
- 오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴
SELECT * FROM raw_data.Vital v LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID; -
userid vitalid date weight alertid vitalid_1 alerttype date_1 userid_1 100 1 2020-01-01 75 None None None None None 100 3 2020-01-02 78 None None None None None 101 2 2020-01-01 90 None None None None None 101 4 2020-01-02 95 1 4 WeightIncrease 2020-01-01 101 
FULL JOIN
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴함
- 매칭되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 리턴
SELECT * FROM raw_data.Vital v FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID; -
userid vitalid date weight alertid vitalid_1 alerttype date_1 userid_1 101 4 2020-01-02 95 1 4 WeightIncrease 2020-01-01 101 None None None None 2 None MissingVital 2020-01-04 100 None None None None 3 None MissingVital 2020-01-04 101 101 2 2020-01-01 90 None None None None None 100 1 2020-01-01 75 None None None None None 100 3 2020-01-02 78 None None None None None 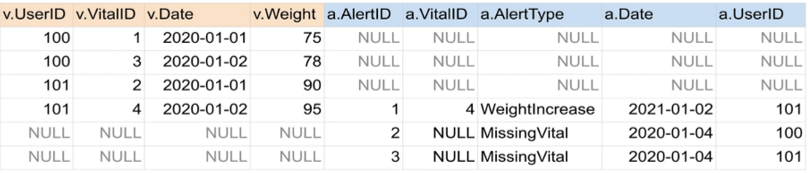
CROSS JOIN (CARTESIAN JOIN)
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴함
- 조인 조건 없이 두 개 테이블의 내용을 모두 조합한 결과 레코드들을 생성
SELECT * FROM raw_data.Vital v CROSS JOIN raw_data.Alert a; -
userid vitalid date weight alertid vitalid_1 alerttype date_1 userid_1 100 1 2020-01-01 75 1 4 WeightIncrease 2020-01-01 101 100 3 2020-01-02 78 1 4 WeightIncrease 2020-01-01 101 101 2 2020-01-01 90 1 4 WeightIncrease 2020-01-01 101 101 4 2020-01-02 95 1 4 WeightIncrease 2020-01-01 101 100 1 2020-01-01 75 2 None MissingVital 2020-01-04 100 100 3 2020-01-02 78 2 None MissingVital 2020-01-04 100 101 2 2020-01-01 90 2 None MissingVital 2020-01-04 100 101 4 2020-01-02 95 2 None MissingVital 2020-01-04 100 100 1 2020-01-01 75 3 None MissingVital 2020-01-04 101 100 3 2020-01-02 78 3 None MissingVital 2020-01-04 101 101 2 2020-01-01 90 3 None MissingVital 2020-01-04 101 101 4 2020-01-02 95 3 None MissingVital 2020-01-04 101 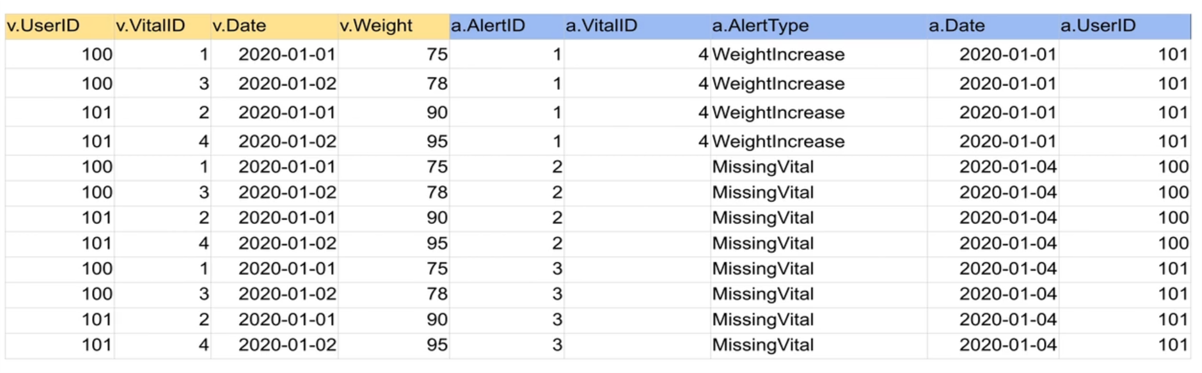
-
SELECT * FROM ( SELECT vitalid -- 1,2,3,4 FROM raw_data.vital ) CROSS JOIN ( SELECT alertid -- 1,2,3 FROM raw_data.alert ); -
vitalid alertid 1 1 1 2 1 3 3 1 3 2 3 3 2 1 2 2 2 3 4 1 4 2 4 3
SELF JOIN
- 동일한 테이블을
alias다르게해서 자신과 조인 -
SELECT * FROM raw_data.Vital v1 JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID; -
userid vitalid date weight userid_1 vitalid_1 date_1 weight_1 100 1 2020-01-01 75 100 1 2020-01-01 75 100 3 2020-01-02 78 100 3 2020-01-02 78 101 2 2020-01-01 90 101 2 2020-01-01 90 101 4 2020-01-02 95 101 4 2020-01-02 95 
3일차 숙제 리뷰
숙제
지금까지 session_timestamp와 user_session_channel을 사용
채널별 월 매출액 테이블 만들기 (본인 스키마 밑에 CTAS로 테이블 만들기)
- session_timestamp, user_session_channel, session_transaction 테이블들 사용
- 아래와 같은 필드로 구성
- month
- channel
- uniqueUsers(총방문 사용자)
- paidUsers(구매 사용자: refund한 경우도 판매로 고려)
- conversionRate(구매 사용자/ 총방문 사용자)
- grossRevenue(refund 포함)
- netRevenue(refund 제외)
BOOLEAN 타입 처리
- True or False
- 다음 2개는 동일한 표현
flag = Trueflag is True
- 다음 2개는 동일한 표현인가
flag is Trueflag is not False- flag가 NULL 일 수도 있음
- raw_data.boolean_test
-
flag True False True None False flag is True인 경우는True2개 이므로 count 2flag is not False인 경우는True2개 와NULL1개 이므로 count 3
-
-
SELECT COUNT(CASE WHEN flag = True THEN 1 END) true_cnt1, COUNT(CASE WHEN flag is True THEN 1 END) true_cnt2, COUNT(CASE WHEN flag is not False THEN 1 END) not_false_cnt FROM raw_data.boolean_test; -
-
true_cnt1 true_cnt2 not_false_cnt 2 2 3
-
NULL 비교
NULL비교는 항상IS혹은IS NOT으로 수행NULL비교를=혹은!=혹은<>로 수행하면 잘못된 결과가 나옴- raw_data.boolean_test
-
flag True False True None False
-
-
SELECT COUNT(1) FROM raw_data.boolean_test WHERE flag is NULL; -
-
count 1
-
-
- flag 가 NULL 인 경우는 1개 뿐임
-
SELECT COUNT(1) FROM raw_data.boolean_test WHERE flag = NULL; -
-
count 0
-
-
=을 썼기 때문에 0 이 나옴.
숙제풀이
채널별 월 매출액 테이블 만들기
유일한 사용자 수 세기
SELECT LEFT(ts,7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
복잡한 JOIN 시 먼저 JOIN 전략부터 수립
raw_data.user_session_channelraw_data.session_timestampraw_data.session_transaction- 위의 3개 테이블 모두
sessionid를 기반으로 조인을 해야함 user_session_channel과session_timestamp는일대일로 조인가능:INNER JOIN- 하지만
session_transaction의 경우에는 모든sessionid가 존재하지 않음
LEFT JOIN(혹은RIGHT JOIN)- FROM 에 사용하는 테이블은
user_session_channel혹은session_timestamp가 되어야 함
- 위의 3개 테이블 모두
session_transaction 테이블 추가
SELECT LEFT(ts,7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid -- added
GROUP BY 1, 2
ORDER BY 1, 2;
paidUsers 추가
SELECT LEFT(ts,7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers, -- added
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
conversionRate 추가
정수 나누기 Issue
- 첫 번째 시도
paidUsers/uniqueUsersASconversionRate
- 두 번째 시도
paidUsers::float/uniqueUsersASconversionRate- float 으로 return 됨
- 세 번째 시도
ROUND(paidUsers*100.0/uniqueUsers, 2)ASconversionRate- float 으로 했지만 paidUsers가 integer이기 때문에 integer * float = integer (much powerful type)
- 네 번째 시도
ROUND(paidUsers*100.0/NULLIF(uniqueUsers, 0) , 2)ASconversionRate- 만약에,
uniqueUsers가 0일 경우, divide by zero는 불가능 NULLIF(uniqueUsers, 0)는 만약에,uniqueUsers가 0일 경우, 0 대신NULL을 사용.NULLIF의 인자로 들어오는 조건이 동일하면 NULL을 return.NULLIF(expr1, expr2)- The
NULLIF()function returns NULL if two expressions are equal, otherwise it returns the first expression.
NULL이 사칙연산에 들어가면 그 결과도 NULL 이기 때문.SELECT LEFT(ts,7) "month", -- "year month" usc.channel, COUNT(DISTINCT userid) uniqueUsers, COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers, ROUND(paidUsers::float*100/NULLIF(uniqueUsers, 0), 2) conversionRate, -- added SUM(amount) grossRevenue, -- added SUM(CASE WHEN refunded is False THEN amount END) netRevenue -- added FROM raw_data.user_session_channel usc LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid-- added LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid GROUP BY 1, 2 ORDER BY 1, 2;
COALESCE
- NULL 값을 다른 값으로 바꿔주는 함수
- 즉, NULL 대신에 다른 백업값을 리턴해주는 함수
COALSE(exp1, exp2, exp3, ...)- exp1 부터 인자를 하나씩 살펴서 NULL이 아닌 값이 나오면 그걸 리턴
- 끝까지 갔는데도 모두 NULL 이면 최종적으로 NULL 을 리턴
- The
COALESCE()function returns the first non-null value in a list.
- raw_data.count_test
-
NULL 1 1 0 0 4 3
-
-
SELECT value, COALESCE(value, 0) --value가 NULL 이면 0을 리턴 FROM raw_data.count_test;
공백 혹은 예약키워드를 필드 이름으로 사용하기
""로 둘러싸서 사용 (double quotes)-
CREATE TABLE keeyong.test ( group int primary key, 'mailing address' varchar(32) ) -
- group 이 이미 예약키워드로 사용되고 있다면 에러가 나오고
-
'mailing address': single quote 에러가 남.
-
DROP TABLE IF EXISTS adhoc.keeyong_monthly_channel_summary; -- 혹시 기존에 생성되어 있으면 삭제 -- added CREATE TABLE adhoc.keeyong_monthly_channel_summary AS -- Summary Table 생성 -- added SELECT LEFT(ts, 7) "month", -- added channel, COUNT(DISTINCT usc.userid) uniqueUsers, COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers, ROUND(paidUsers::float*100/NULLIF(uniqueUsers,0),2) conversionRate, SUM(amount) grossRevenue, SUM(CASE WHEN refunded is False THEN amount ELSE 0 END) netRevenue FROM raw_data.user_session_channel usc LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid GROUP BY 1, 2;
숙제 리뷰
1. 혹시 OUT JOIN이 필요한지, 테이별 점검 필요
select distinct sessionid from raw_data.session_timestamp
minus
select distinct sessionid from raw_data.user_session_channel
;
-- 0 rows affected.
-- sessionid
select distinct sessionid from raw_data.user_session_channel
minus
select distinct sessionid from raw_data.session_timestamp
;
-- 0 rows affected.
-- sessionid
select * from raw_data.session_transaction
where amount <= 0
-- 10 rows affected.
-- sessionid refunded amount
-- 3d194d58a6470121c92f29c1ee4c936f False 0
-- 50aaa83c9c2d1d1f3ebc6c732c1abc8c False 0
-- 7fbfc161a3b873bf2119c788ed93d1f4 False 0
-- d288a67e5fe3b80c0ccb9531e87d437a False 0
-- dfc95d616451863a4fe614534e08261c False 0
-- 297b51d372955449d68d0b67ffda8c80 False 0
-- 52660fd5af844425740f3a7bf5151008 False 0
-- 99e17fbe90095024e6c982c85d43d150 False 0
-- d572948a93127fa250a9aa8a122a4403 False 0
-- e00747f11c12e85717de726cc6c2f188 False 0
2. Summary Table 만들기
SELECT LEFT(ts, 7) "month", -- "year month"
channel,
COUNT(DISTINCT usc.userid) uniqueUsers,
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers,
ROUND(paidUsers*100.0/NULLIF(uniqueUsers, 0),2) conversionRate,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is False THEN amount END) netRevenue
FROM raw_data.user_session_channel usc
LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
-- 42 rows affected.
-- month channel uniqueusers paidusers conversionrate grossrevenue netrevenue
-- 2019-05 Facebook 247 14 5.67 1199 997
-- 2019-05 Google 253 10 3.95 580 580
-- 2019-05 Instagram 234 11 4.70 959 770
-- 2019-05 Naver 237 11 4.64 867 844
-- 2019-05 Organic 238 17 7.14 1846 1571
-- 2019-05 Youtube 244 9 3.69 529 529
-- ...
-- 2019-10 Naver 713 32 4.49 2695 2695
-- 2019-10 Organic 709 31 4.37 2762 2608
-- 2019-10 Youtube 705 34 4.82 2492 2319
-- 2019-11 Facebook 688 25 3.63 1678 1678
-- 2019-11 Google 688 26 3.78 2286 2235
-- 2019-11 Instagram 669 25 3.74 2116 2116
-- 2019-11 Naver 667 26 3.90 2234 1987
-- 2019-11 Organic 677 34 5.02 2626 2255
-- 2019-11 Youtube 677 45 6.65 3532 3331
--혹시 기존에 생성되어 있으면 삭제
DROP TABLE IF EXISTS adhoc.keeyong_monthly_channel_summary;
--Summary Table 생성
CREATE TABLE adhoc.keeyong_monthly_channel_summary
AS
SELECT TO_CHAR(ts, 'YYYY-MM') year_month,
usc.channel,
COUNT(DISTINCT usc.userid) unique_users,
COUNT(DISTINCT CASE WHEN amount>0 THEN userid END) paid_users,
ROUND(paid_users*100./NULLIF(unique_users,0),2) conversion_rate,
SUM(amount) gross_revenue,
SUM(CASE WHEN refunded is False THEN amount
ELSE 0 END) net_revenue
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
LEFT JOIN raw_data.session_transaction str ON usc.sessionid = str.sessionid
GROUP BY 1, 2;
--정상적으로 생성되었는지 확인
SELECT * FROM adhoc.keeyong_monthly_channel_summary;
-- 42 rows affected.
-- year_month channel unique_users paid_users conversion_rate gross_revenue net_revenue
-- 2019-05 Organic 238 17 7 1846 1571
-- 2019-05 Facebook 247 14 5 1199 997
-- 2019-05 Instagram 234 11 4 959 770
-- 2019-07 Facebook 558 32 5 2222 2144
-- 2019-08 Facebook 611 18 2 1009 1009
-- 2019-08 Google 610 27 4 2210 1894
-- 2019-09 Facebook 597 27 4 2270 2270
-- ...
-- 2019-06 Instagram 410 21 5 1462 1418
-- 2019-07 Instagram 567 24 4 1896 1766
-- 2019-08 Organic 608 26 4 1643 1606
-- 2019-08 Youtube 614 18 2 987 950
-- 2019-09 Organic 592 22 3 1267 1267
-- 2019-09 Instagram 588 20 3 1260 1122
-- 2019-10 Organic 709 31 4 2762 2608
-- 2019-10 Instagram 707 33 4 2568 2395
-- 2019-11 Youtube 677 45 6 3532 3331
-- 2019-11 Instagram 669 25 3 2116 2116
SELECT *
FROM raw_data.count_test;
-- 7 rows affected.
-- value
-- None
-- 1
-- 1
-- 0
-- 0
-- 4
-- 3
SELECT
value,
COALESCE(value, 0)
FROM raw_data.count_test;
-- 7 rows affected.
-- value coalesce
-- None 0
-- 1 1
-- 1 1
-- 0 0
-- 0 0
-- 4 4
-- 3 3
숙제
1. 사용자별로 처음 채널과 마지막 채널 알아내기
- ROW_NUMBER vs. FIRST_VALUE/LAST_VALUE
- 사용자 251번의 시간순으로 봤을 때 첫 번째 채널과 마지막 채널은 무엇인가?
- 아래 쿼리를 실행해서 처음과 마지막 채널을 보면 됨
-
SELECT ts, channel FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid WHERE userid = 251 ORDER BY 1
- ROW_NUMBER 를 이용해서 해보자
- ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2) nn
ROW_NUMBER 설명
- 사용자별로 시간순으로 일련번호를 매기고 싶다면
- 새로운 컬럼 추가
- 사용자별로 레코드를 모으고 그 안에서 시간순으로 sort 후 사용자별로 1부터 번호 부여
- ROW_NUMBER를 쓰면 2를 구현 가능
- ROW_NUMBER OVER (partition by userid order by ts) seq
2. Gross Revenue 가 가장 큰 UserID 10개 찾기
- user_session_channel 과 session_transaction 과 session_timestamp 테이블을 사용
- Gross revenue: Refund 포함한 매출
3. raw_data.nps 테이블을 바탕으로 월별 NPS 계산
- 고객들이 0 (의향없음) 에서 10 (의향 아주 높음)
- detractor (비추천자): 0 에서 6
- passive (소극자): 7이나 8점
- promoter (홍보자): 9 나 10점
- NPS = promoter 퍼센트 - detractor 퍼센트
Leave a comment