
Big data - SparkSQL을 이용한 데이터 분석
커리어 이야기
- 남과 비교하지 말고 앞으로 20-30년을 보기
- 하나를 하기로 했으면 적어도 6개월은 파고 들기
- 너무 빨리 포기하지 않기
- 뭔가 잘 안되면 서두르기 보다는 오히려 천천히 가기
- 공부를 위한 공부를 하기 보다는 일을 시작해보기
- 어디건 일을 시작하고 발전해 나가기
- 면접 실패를 감정적으로 받아들이지 않기
새로운 시작 - 처음 90일이 중요
- 자기 검열하지 말고 매니저의 스타일 파악하고 피드백 요청
- 과거의 상처 가지고 시작하지 않기
- 남과 비교하지 않기
- 열심히 일하되 너무 서두르지 않기
새로운 기술의 습득이 아닌 결과를 내는데 초점 맞추기
- 아주 나쁘지 않은 환경에 있다는 전제
- 자신이 맡은 일을 잘 하기 위해서 필요한 기술습득
- 예를 들면 자동화하기 혹은 실행시간 단축하기
- 자신이 맡은 일의 성공/실패를 어떻게 결정하는지 생각
- 매니저와의 소통이 중요
- 성공/실패 지표에 대해서 생각
- 일을 그냥 하지 말고 항상 “왜” 이 일이 필요하고 큰 그림을 생각
- 질문하기
SQL 이란
SQL 은 빅데이터 세상에서도 중요
- 구조화된 데이터를 다루는 한 SQL은 데이터 규모와 상관없이 쓰임
- 모든 대용량 데이터 웨어하우스는 SQL 기반
- Redshift, Snowflake, BigQuery, Hive
- Spark도 예외는 아님
- SparkSQL이 지원
- 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술
관계형 데이터 베이스
- 대표적인 관계형 데이터 베이스
- MySQL, Postgres, Oracle, …
- Redshift, Snowflake, BigQuery, Hive, …
- 관계형 데이터베이스는 2단계로 구성
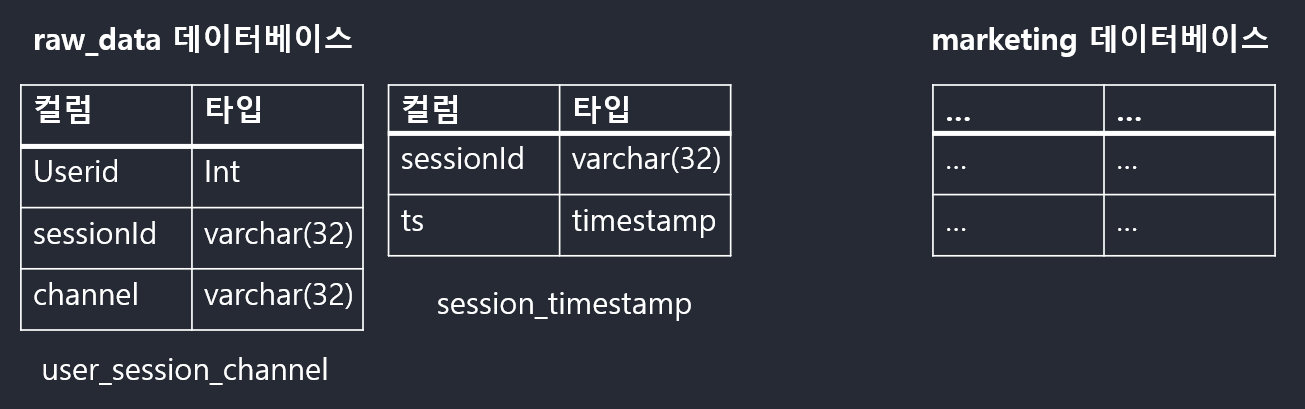
- 가장 밑단에는 테이블들이 존재 (테이블은 엑셀의 시트에 해당)
- 테이블들은 데이터베이스라는 폴더 밑으로 구성
- 테이블의 구조 (스키마라도 부르기도함)
- 테이블은 레코드들로 구성
- 레코드는 하나 이상의 필드로 구성
- 필드는 이름과 타입으로 구성
관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보
- 사용자 ID:
- 보통 웹서비스에서는 등록된 사용자마다 유일한 ID를 부여 ⇒ 사용자 ID
- 세션 ID:
- 사용자가 외부 링크 (보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성
- 즉 하나의 사용자 ID는 여러 개의 세션 ID를 가질 수 있음
- 보통 세션의 경우 세션을 만들어낸 소스를 채널이란 이름으로 기록해둠
- 마케팅 관련 기여도 분석을 위함
- 또한 세션이 생긴 시간도 기록
- 이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능
- 마케팅 관련
- 사용자 트래픽 관련
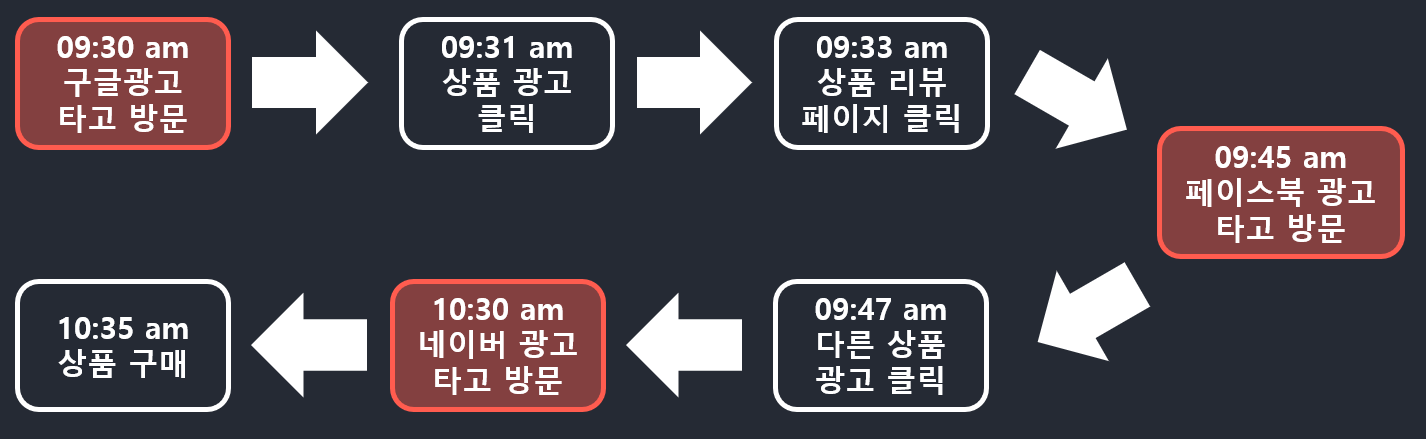
- 사용자 ID 100번: 총 3개의 세션(painted)을 갖는 예제
- 세션 1: 구글 키워드 광고로 시작한 세션
- 세션 2: 페이스북 광고를 통해 생긴 세션
- 세션 3: 네이버 광고를 통해 생긴 세션
관계형 데이터베이스 예제 - 데이터베이스와 테이블
SQL 소개
- SQL: Structured Query Language
- SQL은 1970년대 초반에 IBM 이 개발한 구조화된 데이터 질의 언어
- 주로 관계형 데이터베이스에 있는 데이터를 질의 하는 언어
- 두 종류의 언어로 구성됨
- DDL (Data Definition Language)
- 테이블의 구조를 정의하는 언어
- DML (Data Manipulation Language)
- 테이블에 레코드를 추가/삭제/갱신 해주는데 사용하는 언어
- DDL (Data Definition Language)
SQL DDL - 테이블 구조 정의 언어
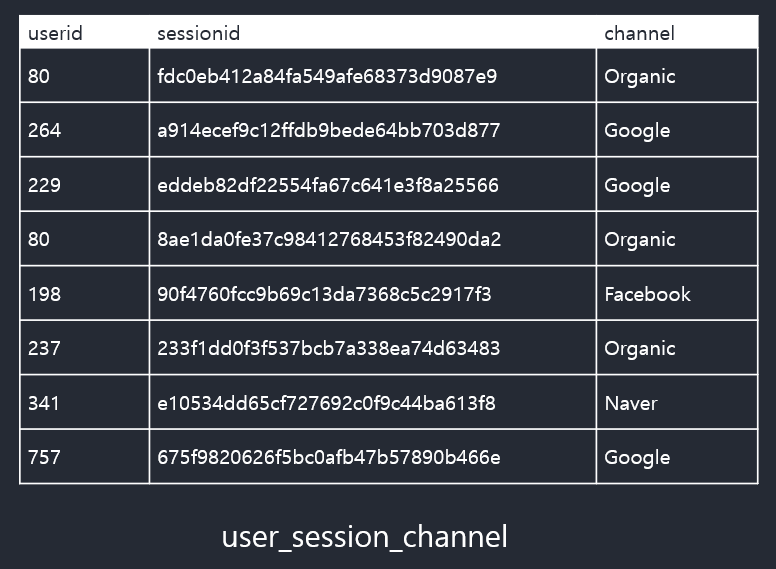
CREATE TABLEDROP TABLEALTER TABLEraw_data폴더에user_session_channel라는 이름인 테이블을 생성CREATE TABLE raw_data.user_session_channel ( userid int, sessionid varchar(32), channel varchar(32) );
SQL DML - 테이블 데이터 조작 언어
SELECT FROM: 테이블에서 레코드와 필드를 읽어오는데 사용- 보통 다수의 테이블의 조인해서 사용
INSERT FROM: 테이블에 레코드를 추가하는데 사용UPDATE FROM: 테이블의 레코드를 수정DELETE FROM: 테이블에서 레코드를 삭제SELECT 필드이름1, 필드이름2, ... FROM 테이블이름 WHERE 선택조건 ORDER BY 필드이름 [ASC|DESC] LIMIT NSELECT * FROM raw_data.user_session_channel LIMIT 10;SELECT COUNT(1) FROM raw_data.user_session_channel;SELECT COUNT(1) FROM raw_data.user_session_channel WHERE channel = 'Facebook'; --channel 이름이 Facebook인 경우만SELECT COUNT(1) FROM raw_data.user_session_channel WHERE channel ilike '%o%'; --channel 이름에 o나 O가 있는 경우만 (%: filesystem 에서 *에 해당)SELECT channel, COUNT(1) --channel 별로 레코드수 카운트하기 FROM raw_data.user_session_channel GROUP BY channel;- 세션에 대한 모든 정보 읽어오기: user_session_channel 과 session_timestamp 조인하기
SELECT * FROM raw_data.user_session_channel usc JOIN raw_data.session_timestamp ts ON usc.sessionID = ts.sessionID;
SQL 실습 - Redshift 기반 SQL 실습
%%sql
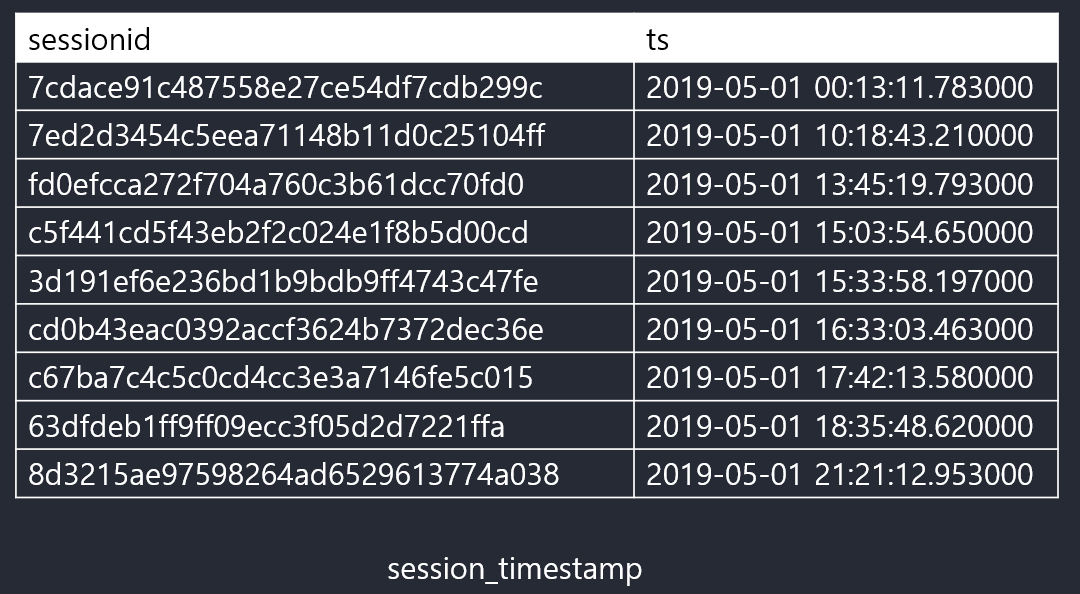
SELECT * FROM raw_data.session_timestamp LIMIT 10;
-- sessionid ts
-- 7cdace91c487558e27ce54df7cdb299c 2019-05-01 00:13:11.783000
-- 7ed2d3454c5eea71148b11d0c25104ff 2019-05-01 10:18:43.210000
-- fd0efcca272f704a760c3b61dcc70fd0 2019-05-01 13:45:19.793000
-- c5f441cd5f43eb2f2c024e1f8b5d00cd 2019-05-01 15:03:54.650000
-- 3d191ef6e236bd1b9bdb9ff4743c47fe 2019-05-01 15:33:58.197000
-- cd0b43eac0392accf3624b7372dec36e 2019-05-01 16:33:03.463000
-- c67ba7c4c5c0cd4cc3e3a7146fe5c015 2019-05-01 17:42:13.580000
-- 63dfdeb1ff9ff09ecc3f05d2d7221ffa 2019-05-01 18:35:48.620000
-- 8d3215ae97598264ad6529613774a038 2019-05-01 21:21:12.953000
-- 4c4c937b67cc8d785cea1e42ccea185c 2019-05-01 23:50:38
%%sql
SELECT DATE(ts) date, sessionID FROM raw_data.session_timestamp LIMIT 10; --DATE(ts): 날짜만 리턴
-- date sessionid
-- 2019-05-01 7cdace91c487558e27ce54df7cdb299c
-- 2019-05-01 7ed2d3454c5eea71148b11d0c25104ff
-- 2019-05-01 fd0efcca272f704a760c3b61dcc70fd0
-- 2019-05-01 c5f441cd5f43eb2f2c024e1f8b5d00cd
-- 2019-05-01 3d191ef6e236bd1b9bdb9ff4743c47fe
-- 2019-05-01 cd0b43eac0392accf3624b7372dec36e
-- 2019-05-01 c67ba7c4c5c0cd4cc3e3a7146fe5c015
-- 2019-05-01 63dfdeb1ff9ff09ecc3f05d2d7221ffa
-- 2019-05-01 8d3215ae97598264ad6529613774a038
-- 2019-05-01 4c4c937b67cc8d785cea1e42ccea185c
%%sql
SELECT DATE(ts) date, sessionID FROM raw_data.session_timestamp ORDER BY ts desc LIMIT 10; --ts 순으로 sorting 내림차순
-- date sessionid
-- 2019-11-30 6309ff4befccf8ba77b16141fab763c6
-- 2019-11-30 42daed3b750cc5c6270636fddee0486d
-- 2019-11-30 398c674511e98d3e9bd40ba5bfa67af8
-- 2019-11-30 1e65c9f788d6382abc0ee60886e7fa4a
-- 2019-11-30 ec6d363a01a8a0691d24b8556bc1fb61
-- 2019-11-30 8f48bd8292fc4540404dc9dae06175e6
-- 2019-11-30 89a76004709bb668a8aefb6306a6aed1
-- 2019-11-30 9cfaefd1e81f637fad6330ff16eb1f39
-- 2019-11-30 bbf2f1c020c5e39734c73223784bd7b4
-- 2019-11-30 bac82af401b714e895c9c46af11f76ea
%%sql
SELECT DATE(ts) date, COUNT(sessionID)
FROM raw_data.session_timestamp
GROUP BY 1
LIMIT 10; --일별(GROUP BY 1(DATE(ts))) 세션 아이디 카운트하기
-- date count
-- 2019-05-01 147
-- 2019-05-02 161
-- 2019-05-03 150
-- 2019-05-04 142
-- 2019-05-06 164
-- 2019-05-07 180
-- 2019-05-08 161
-- 2019-05-10 176
-- 2019-05-12 171
-- 2019-05-13 178
%%sql
SELECT DATE(ts) date, COUNT(sessionID)
FROM raw_data.session_timestamp
GROUP BY 1
ORDER BY 1
LIMIT 10; --일별(GROUP BY 1(DATE(ts))) 세션 아이디 카운트하기
-- date count
-- 2019-05-01 147
-- 2019-05-02 161
-- 2019-05-03 150
-- 2019-05-04 142
-- 2019-05-05 144
-- 2019-05-06 164
-- 2019-05-07 180
-- 2019-05-08 161
-- 2019-05-09 169
-- 2019-05-10 176
JOIN 에 대해 배워보자. 일별 방문 유니크한 사용자의 수를 계산하고 싶다면
# raw_data.user_session_channel과 raw_data.session_timestamp 테이블의 조인이 필요
%%sql
SELECT DATE(st.ts) date, COUNT(usc.userID)
FROM raw_data.session_timestamp st
JOIN raw_data.user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
LIMIT 10;
-- date count
-- 2019-05-01 147
-- 2019-05-02 161
-- 2019-05-03 150
-- 2019-05-04 142
-- 2019-05-05 144
-- 2019-05-06 164
-- 2019-05-07 180
-- 2019-05-08 161
-- 2019-05-09 169
-- 2019-05-10 176
하지만 한 사용자가 여러개의 세션을 가질 수 있음
COUNT(usc.sessionID)는 이를 반영하지 못함.
이것은 overcounting이 되었을 가능성이 높음.
(사실 세션을 카운팅한것과 다를게 없음)
%%sql
SELECT DATE(st.ts) date, COUNT(DISTINCT usc.userID)
FROM raw_data.session_timestamp st
JOIN raw_data.user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
LIMIT 10;
-- date count
-- 2019-05-01 119
-- 2019-05-02 127
-- 2019-05-03 130
-- 2019-05-04 122
-- 2019-05-05 124
-- 2019-05-06 133
-- 2019-05-07 147
-- 2019-05-08 135
-- 2019-05-09 145
-- 2019-05-10 144
DISTINCT를 사용해서 해결
채널별로 유니크한 사용자수 카운팅하기
%%sql
SELECT channel, COUNT(DISTINCT usc.userID)
FROM raw_data.session_timestamp st
JOIN raw_data.user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
LIMIT 10;
-- channel count
-- Facebook 889
-- Google 893
-- Instagram 895
-- Naver 882
-- Organic 895
-- Youtube 889
%%sql
SELECT DISTINCT channel FROM raw_data.user_session_channel
WHERE channel ilike '%o%'
-- channel
-- Organic
-- Google
-- Facebook
-- Youtube
%%sql
SELECT DISTINCT channel FROM raw_data.user_session_channel
WHERE channel like '%o%'
-- channel
-- Facebook
-- Youtube
-- Google
%%sql
SELECT COUNT(1) FROM raw_data.user_session_channel
WHERE channel ilike '%o%'; --user_session_channel 레코드들 중에 channel 에 대소문자 'o'가 들어간 레코드들을 카운트 해라.
-- count
-- 67768
판다스와 연동하는 방법
result = %sql SELECT * FROM raw_data.user_session_channel
df = result.DataFrame()
pandas로 변환하니 컬럼명이 소문자로 되어버림.
df.head()
# userid sessionid channel
# 0 184 c41dd99a69df04044aa4e33ece9c9249 Naver
# 1 251 0a54b19a13b6712dc04d1b49215423d8 Facebook
# 2 744 05ae14d7ae387b93370d142d82220f1b Facebook
# 3 265 4c4ea5258ef3fb3fb1fc48fee9b4408c Naver
# 4 45 60131a2a3f223dc8f4753bcc5771660c Youtube
df.groupby(['channel']).size()
# channel
# Facebook 16791
# Google 16982
# Instagram 16831
# Naver 16921
# Organic 16904
# Youtube 17091
# dtype: int64
df.groupby(['channel'])['sessionid'].count()
# channel
# Facebook 16791
# Google 16982
# Instagram 16831
# Naver 16921
# Organic 16904
# Youtube 17091
# Name: sessionid, dtype: int64
%%sql
SELECT channel, COUNT(st.sessionID)
FROM raw_data.session_timestamp st
JOIN raw_data.user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
-- channel count
-- Facebook 16791
-- Google 16982
-- Instagram 16831
-- Naver 16921
-- Organic 16904
-- Youtube 17091
result = %sql SELECT * FROM raw_data.session_timestamp
df_st = result.DataFrame()
df_st.head()
# sessionid ts
# 0 94f192dee566b018e0acf31e1f99a2d9 2019-05-01 00:49:46.073
# 1 f1daf122cde863010844459363cd31db 2019-05-01 13:10:56.413
# 2 8804f94e16ba5b680e239a554a08f7d2 2019-05-01 14:23:07.660
# 3 d5fcc35c94879a4afad61cacca56192c 2019-05-01 15:13:16.140
# 4 c17028c9b6e0c5deaad29665d582284a 2019-05-01 15:59:57.490
df_st['date'] = df_st['ts'].apply(lambda x: "%d-%02d-%02d" % (x.year, x.month, x.day))
df_st.head()
# sessionid ts date
# 0 94f192dee566b018e0acf31e1f99a2d9 2019-05-01 00:49:46.073 2019-05-01
# 1 f1daf122cde863010844459363cd31db 2019-05-01 13:10:56.413 2019-05-01
# 2 8804f94e16ba5b680e239a554a08f7d2 2019-05-01 14:23:07.660 2019-05-01
# 3 d5fcc35c94879a4afad61cacca56192c 2019-05-01 15:13:16.140 2019-05-01
# 4 c17028c9b6e0c5deaad29665d582284a 2019-05-01 15:59:57.490 2019-05-01
df_st.groupby(['date']).size() #.sort_values(['date'])
-- date
-- 2019-05-01 147
-- 2019-05-02 161
-- 2019-05-03 150
-- 2019-05-04 142
-- 2019-05-05 144
-- ...
-- 2019-11-26 633
-- 2019-11-27 617
-- 2019-11-28 516
-- 2019-11-29 531
-- 2019-11-30 562
-- Length: 214, dtype: int64
df_st.groupby(['date'])['sessionid'].count().reset_index(name='count').sort_values('date',ascending=False)
# date count
# 213 2019-11-30 562
# 212 2019-11-29 531
# 211 2019-11-28 516
# 210 2019-11-27 617
# 209 2019-11-26 633
# ... ... ...
# 4 2019-05-05 144
# 3 2019-05-04 142
# 2 2019-05-03 150
# 1 2019-05-02 161
# 0 2019-05-01 147
# 214 rows × 2 columns
SparkSQL 이란
- 구조화된 데이터 처리를 위한 Spark 모듈
- 대화형 Spark 셸이 제공됨
- 하둡 상의 데이터를 기반으로 작성된 Hive 쿼리의 경우 변경없이 최대 100배 까지 빠른 성능
- 데이터 프레임을 SQL 로 처리 가능
- RDD 데이터는 결국 데이터 프레임으로 변환한 후에 처리 가능
- 외부 데이터(스토리지나 관계형 데이터베이스)는 데이터프레임으로 변환후 가능
- 데이터프레임은 테이블이 되고 (특정 함수 사용) 그 다음부터
sql함수를 사용 가능
SparkSQL 사용법 - 외부 데이터베이스 연결
외부 데이터베이스 기반으로 데이터 프레임 생성
SparkSession의read함수를 사용하여 테이블 혹은SQL결과를 데이터프레임으로 읽어옴- Redshift 연결 예제
SparkSession을 만들때 외부 데이터베이스에 맞는JDBC jar을 지정SparkSession의read함수를 호출- 로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정
- 결과가 데이터 프레임으로 리턴됨
- 앞서 리턴된 데이터프레임에 테이블 이름 지정
SparkSession의sql함수를 사용
SparkSession을 만들 때 외부 데이터베이스에 맞는 JDBC jar을 지정
- Redshift 연결 예. 구글 colab에서 설치는 약간 복잡
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("Python Spark SQL basic example").config("spark.jars",".....").getOrCreate()
SparkSession 의 read 함수 호출 (로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정)
- 결과가 데이터프레임으로 리턴됨
df_user_session_channel = spark.read.format("jdbc")\ .option("driver","com.amazon.redshift.jdbc42.Driver")\ .option("url","jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/prod?user=guest&password=Guest1!*").\ .option("dbtable","raw_data.user_session_channel")\ .load()
SparkSQL 사용법 - SQL 사용 방법
- 데이터 프레임을 기반으로 테이블 뷰 생성: 테이블이 만들어짐
- createOrReplaceTempView: SparkSession 이 살아있는 동안 존재
- createGlobalTempView: Spark 드라이버가 살아있는 동안 존재
- SparkSession 의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1")
print(namegender_group_df.collect()) # collect 로 받아야 로컬로 데이터가 오는 것임.(그렇지 않을 경우 spark 클러스터에만 있기 때문.)
SparkSQL 실습
구글 Colab 기반 SparkSQL 실습
실습내용
Redshift SQL 로 했던 분석을 SparkSQL로 다시 해보기
- SQL로 할 수 있는 일과 판다스로 할 수 있는 일이 굉장히 흡사함을 경험
- SparkSQL로 할 수 있는 일과 Spark DataFrame으로 할 수 있는 일이 비슷함을 경험하게 됨
실습 노트북
노트북
PySpark을 로컬머신에 설치하고 노트북을 사용하기 보다는 머신러닝 관련 다양한 라이브러리가 이미 설치되었고 좋은 하드웨어를 제공해주는 Google Colab을 통해 실습을 진행한다.
이를 위해 pyspark과 Py4J 패키지를 설치한다. Py4J 패키지는 파이썬 프로그램이 자바가상머신상의 오브젝트들을 접근할 수 있게 해준다. Local Standalone Spark을 사용한다.
!pip install pyspark==3.0.1 py4j==0.10.9
지금부터 실습은 Redshift에 있는 데이터를 가지고 해볼 예정이고 그래서 Redshift 관련 JAR 파일을 설치해야함
!cd /usr/local/lib/python3.7/dist-packages/pyspark/jars && wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.20.1043/RedshiftJDBC42-no-awssdk-1.2.20.1043.jar
Spark Session: 이번 SparkSession은 spark.jars를 통해 앞서 다운로드받은 Redshift 연결을 위한 JDBC 드라이버를 사용함 (.config("spark.jars", ...)
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.jars", "/usr/local/lib/python3.7/dist-packages/pyspark/jars/RedshiftJDBC42-no-awssdk-1.2.20.1043.jar") \
.getOrCreate()
spark
SparkSQL 맛보기
판다스로 일단 CSV 파일 하나 로드하기
import pandas as pd
namegender_pd = pd.read_csv("https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv")
namegender_pd.head()
namegender_pd.groupby(["gender"]).count()
판다스 데이터프레임을 Spark 데이터프레임으로 변환하기
namegender_df = spark.createDataFrame(namegender_pd)
namegender_df.printSchema()
namegender_df.show()
namegender_df.groupBy(["gender"]).count()의 경우 아직 spark 클러스터에 있는 상태임
collect()를 해줘야 로컬로 받아서 print 형태로 볼 수 있음
namegender_df.groupBy(["gender"]).count()
namegender_df.groupBy(["gender"]).count().collect()
# https://towardsdatascience.com/pyspark-and-sparksql-basics-6cb4bf967e53
데이터프레임을 테이블뷰(테이블 이름을 주고)로 만들어서 SparkSQL로 처리해보기
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1")
namegender_group_df.collect()
Redshift와 연결해서 테이블들을 데이터프레임으로 로딩하기
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1!*") \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1!*") \
.option("dbtable", "raw_data.session_timestamp") \
.load()
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
channel_count_df = spark.sql("""
SELECT channel, count(distinct userId) uniqueUsers
FROM session_timestamp st
JOIN user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
""")
channel_count_df
channel_count_df.show()
Leave a comment